Using SSE to improve the performance. The pictures and the profiling in the comments shows the improvement on an Ryzen 3700X. See also performance comparison P231.
Details
Details
- Reviewers
vladislavbelov wraitii linkmauve Imarok
Try, that everything works correct. Profile and confirm, that the SSE version is an improvement. SSE improvement depends on the CPU. Additional test with the SSE build flag enabled and disabled.
Diff Detail
Diff Detail
- Repository
- rP 0 A.D. Public Repository
- Lint
Lint Skipped - Unit
Unit Tests Skipped - Build Status
Buildable 15558 Build 34176: Vulcan Build Jenkins Build 34175: Vulcan Build (macOS) Jenkins Build 34174: Vulcan Build (Windows) Jenkins
Event Timeline
Comment Actions
Build failure - The Moirai have given mortals hearts that can endure.
Link to build: https://jenkins.wildfiregames.com/job/vs2015-differential/2041/display/redirect
Comment Actions
Successful build - Chance fights ever on the side of the prudent.
Linter detected issues:
Executing section Source...
source/lib/sysdep/compiler.h
| 1| /*·Copyright·(c)·2019·Wildfire·Games.
| | [NORMAL] LicenseYearBear:
| | License should have "2020" year instead of "2019"
source/lib/sysdep/arch/x86_x64/x86_x64.h
| 1| /*·Copyright·(C)·2010·Wildfire·Games.
| | [NORMAL] LicenseYearBear:
| | License should have "2020" year instead of "2010"
source/lib/sysdep/arch/x86_x64/x86_x64.h
| 40| namespace·x86_x64·{
| | [MAJOR] CPPCheckBear (syntaxError):
| | Code 'namespacex86_x64{' is invalid C code. Use --std or --language to configure the language.
source/maths/Matrix3D.h
| 1| /*·Copyright·(C)·2019·Wildfire·Games.
| | [NORMAL] LicenseYearBear:
| | License should have "2020" year instead of "2019"
source/maths/Matrix3D.h
| 39| class·CMatrix3D
| | [MAJOR] CPPCheckBear (syntaxError):
| | Code 'classCMatrix3D{' is invalid C code. Use --std or --language to configure the language.
Executing section JS...
Executing section cli...Link to build: https://jenkins.wildfiregames.com/job/docker-differential/2574/display/redirect
Comment Actions
Would be nice to:
- Understand why compilers can't vectorise these themselves (is it just a build-flag issue?)
- Get some actual profiling in, ideally some Profiler 2 graphs of MP replays.
Comment Actions
From my discussions with Optimus Shepard, the fact that it is using FMA3 is problematic, because it literraly prevents anyone with less an Intel IX-4000 era CPU and FX6000 to play the game. We don't gather stats about those, so we do not actually know how many of our users have such CPUs.
From the 7th percent improvement reported by Optimus Shepard 30% of that is due to the usage of FMA3.
@wraitii on Linux we do not compile with march=native, so it's likely a lot of the code doesn't use the the CPU specific things because else the package would not be compatible depending on the CPU. This is of course not an issue on Mac since most people have the same hardware (Although from the GMP flag issue that causes TLS to crash on some MacOs versions, I guess it's not exactly true.
We also don't passe the flags that allow such compilation on windows see rP16912
Comment Actions
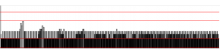


I tested the build flags, SSE seems to be the only flag with an positiv impact. AVX2 makes everything worse. I also made some profiling.
Current version:
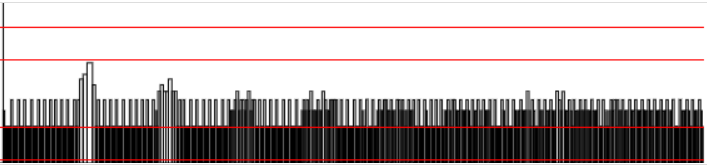
Current Version with SSE flag:

SSE patch:

SSE patch with SSE flag:

As you can see the SSE patch lowers the spikes. You can also see there are less and smaller "black blocks" on the right side, which means also better frametimes.
The impact of the SSE flag is not really noticeable, but for me it looks a bit better than without.
Comment Actions
I have rewrite the patch, so it uses only SSE. That I have used for the profiling. I will upload it later this day.
Comment Actions
Removed the AVX and FMA version, as we don't be able, to change instructions by runtime. Furthermore the AVX instructions aren't faster than SSE here.
Comment Actions
Build failure - The Moirai have given mortals hearts that can endure.
Link to build: https://jenkins.wildfiregames.com/job/docker-differential/2614/display/redirect
Comment Actions
Build failure - The Moirai have given mortals hearts that can endure.
Link to build: https://jenkins.wildfiregames.com/job/macos-differential/982/display/redirect
Comment Actions
Successful build - Chance fights ever on the side of the prudent.
Linter detected issues:
Executing section Source...
source/maths/Matrix3D.h
| 1| /*·Copyright·(C)·2019·Wildfire·Games.
| | [NORMAL] LicenseYearBear:
| | License should have "2020" year instead of "2019"
source/maths/Matrix3D.h
| 38| class·CMatrix3D
| | [MAJOR] CPPCheckBear (syntaxError):
| | Code 'classCMatrix3D{' is invalid C code. Use --std or --language to configure the language.
Executing section JS...
Executing section cli...Link to build: https://jenkins.wildfiregames.com/job/docker-differential/2615/display/redirect
Comment Actions
Successful build - Chance fights ever on the side of the prudent.
Linter detected issues:
Executing section Source...
source/maths/Matrix3D.h
| 38| class·CMatrix3D
| | [MAJOR] CPPCheckBear (syntaxError):
| | Code 'classCMatrix3D{' is invalid C code. Use --std or --language to configure the language.
Executing section JS...
Executing section cli...Link to build: https://jenkins.wildfiregames.com/job/docker-differential/2616/display/redirect
Comment Actions
I like your approach better but interestingly it's done slightly differently in https://github.com/0ad/0ad/blob/d3e68a99e7f715ad7921a81e959f8ac51dfa1248/source/graphics/Color.cpp
Can you figure out what's causing the spikes?
| source/maths/Matrix3D.h | ||
|---|---|---|
| 273 | 0.f here and above :) | |
Comment Actions
Oh, I think they changing the instructions by runtime, doesn't they? A bit ugly, I think, but we could use FMA :)
Can you figure out what's causing the spikes?
I will try, but on an first look, the profiler doesn't show me something useful.
Comment Actions
Didn't find the cause yet. But I recognized, that the profiler gains these pikes very much. Without the framedrops were much lower.
Comment Actions
Is it blend or multiplication that gives the biggest boost? And where are those called ?
Comment Actions
I'm not convinced TBH. If this is hardcoded at compile-time, either we drop support or it's pretty much useless for releases. SIMD-capable compilers seem able to vectorise this functions, so custom versions don't seem particularly useful.
If there was a runtime switch that actually increased performance, might be more interesting.
| source/maths/Matrix3D.h | ||
|---|---|---|
| 147 | For what it's worth, here's what Clang generates for me on SSE3 (NB -> assembly): rdx -> this rsi -> argument Matrix rdi -> return Matrix movss xmm3, dword [rdx] movss xmm4, dword [rdx+4] movss xmm7, dword [rdx+8] movss xmm0, dword [rdx+0xc] movss xmm5, dword [rdx+0x10] movss xmm6, dword [rdx+0x14] movups xmm2, xmmword [rsi] movups xmm1, xmmword [rsi+0x10] shufps xmm3, xmm3, 0x0 mulps xmm3, xmm2 shufps xmm4, xmm4, 0x0 mulps xmm4, xmm1 addps xmm4, xmm3 movups xmm3, xmmword [rsi+0x20] shufps xmm7, xmm7, 0x0 mulps xmm7, xmm3 addps xmm7, xmm4 movups xmm4, xmmword [rsi+0x30] shufps xmm0, xmm0, 0x0 mulps xmm0, xmm4 addps xmm0, xmm7 movss xmm7, dword [rdx+0x18] shufps xmm5, xmm5, 0x0 mulps xmm5, xmm2 shufps xmm6, xmm6, 0x0 mulps xmm6, xmm1 addps xmm6, xmm5 movss xmm5, dword [rdx+0x1c] shufps xmm7, xmm7, 0x0 mulps xmm7, xmm3 addps xmm7, xmm6 movss xmm6, dword [rdx+0x20] shufps xmm5, xmm5, 0x0 mulps xmm5, xmm4 addps xmm5, xmm7 movss xmm7, dword [rdx+0x24] shufps xmm6, xmm6, 0x0 mulps xmm6, xmm2 shufps xmm7, xmm7, 0x0 mulps xmm7, xmm1 addps xmm7, xmm6 movss xmm6, dword [rdx+0x28] shufps xmm6, xmm6, 0x0 mulps xmm6, xmm3 addps xmm6, xmm7 movss xmm7, dword [rdx+0x2c] shufps xmm7, xmm7, 0x0 mulps xmm7, xmm4 addps xmm7, xmm6 movss xmm6, dword [rdx+0x30] shufps xmm6, xmm6, 0x0 mulps xmm6, xmm2 movss xmm2, dword [rdx+0x34] shufps xmm2, xmm2, 0x0 mulps xmm2, xmm1 addps xmm2, xmm6 movss xmm1, dword [rdx+0x38] shufps xmm1, xmm1, 0x0 mulps xmm1, xmm3 addps xmm1, xmm2 movss xmm2, dword [rdx+0x3c] shufps xmm2, xmm2, 0x0 mulps xmm2, xmm4 addps xmm2, xmm1 movups xmmword [rdi], xmm0 movups xmmword [rdi+0x10], xmm5 movups xmmword [rdi+0x20], xmm7 movups xmmword [rdi+0x20], xmm7 movups xmmword [rdi+0x30], xmm2 | |
Comment Actions
The sse_test.patch includes the SSE functions as well as the performance test.
Made some performance profiling on MSVC2017, SSE2 flag enabled, Ryzen 3700X.
matrix multiplication number_of_samples = 200 number_of_iteration = 1000000 have_sse = true SSE (off): 4.42847ms SSE (on): 1.65399ms matrix Blend number_of_samples = 200 number_of_iteration = 1000000 have_sse = true SSE (off): 1.315ms SSE (on): 1.26501ms matrix AddBlend number_of_samples = 200 number_of_iteration = 1000000 have_sse = true SSE (off): 1.3113ms SSE (on): 1.24452ms }
Seems to only the matrix multiplication is really relevant.
The sse_test.patch includes the SSE functions as well as the performance test.
Comment Actions
Yeah I kind of lost track that on other systems we didn't assume SSE, so it could be worth it in those cases.
Comment Actions
So here ist the generated assembly for matrix multiplication, SSE2 flag enabled, MSVC2017.
| source/maths/Matrix3D.h | ||
|---|---|---|
| 147 | So this is the generated assembly for the non-SSE function? It looks nearly the same, as the code that was created by MSVC2017 for the SSE function. The code, which is generated by MSVC2017 for the non-SSE function, is round about 3 times longer. | |
Comment Actions
Rebase, use a dynamic switch. Leave the tests for now to see how they run on the CI. Could be _Disabled
Comment Actions
Build failure - The Moirai have given mortals hearts that can endure.
builderr-debug-gcc7.txt
In file included from ../../../source/simulation2/components/CCmpOverlayRenderer.cpp:18:
../../../source/pch/simulation2/precompiled.h:18:2: error: invalid preprocessing directive #define
#define MINIMAL_PCH 2
^~~~~~
In file included from ../../../source/pch/simulation2/precompiled.h:19,
from ../../../source/simulation2/components/CCmpOverlayRenderer.cpp:18:
../../../source/lib/precompiled.h:35:2: error: invalid preprocessing directive #ifndef
#ifndef MINIMAL_PCH
^~~~~~
../../../source/lib/precompiled.h:36:3: error: invalid preprocessing directive #define
# define MINIMAL_PCH 0
^~~~~~
../../../source/lib/precompiled.h:37:2: error: #endif without #if
#endif
^~~~~
In file included from ../../../source/lib/precompiled.h:39,
from ../../../source/pch/simulation2/precompiled.h:19,
from ../../../source/simulation2/components/CCmpOverlayRenderer.cpp:18:
../../../source/lib/config.h:27:2: error: invalid preprocessing directive #ifndef
#ifndef INCLUDED_CONFIG
^~~~~~
../../../source/lib/config.h:28:2: error: invalid preprocessing directive #define
#define INCLUDED_CONFIG
^~~~~~
../../../source/lib/config.h:40:2: error: invalid preprocessing directive #ifndef
#ifndef CONFIG_ENABLE_PCH
^~~~~~
../../../source/lib/config.h:41:3: error: invalid preprocessing directive #define
# define CONFIG_ENABLE_PCH 1 // improve build performance
^~~~~~
../../../source/lib/config.h:42:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/config.h:45:2: error: invalid preprocessing directive #ifndef
#ifndef CONFIG_OMIT_FP
^~~~~~
../../../source/lib/config.h:46:3: error: invalid preprocessing directive #ifdef
# ifdef NDEBUG
^~~~~
../../../source/lib/config.h:47:4: error: invalid preprocessing directive #define
# define CONFIG_OMIT_FP 1 // improve performance
^~~~~~
../../../source/lib/config.h:48:3: error: #else without #if
# else
^~~~
../../../source/lib/config.h:49:4: error: invalid preprocessing directive #define
# define CONFIG_OMIT_FP 0 // enable use of ia32's fast stack walk
^~~~~~
../../../source/lib/config.h:50:3: error: #endif without #if
# endif
^~~~~
../../../source/lib/config.h:51:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/config.h:55:2: error: invalid preprocessing directive #ifndef
#ifndef CONFIG_DISABLE_EXCEPTIONS
^~~~~~
../../../source/lib/config.h:56:3: error: invalid preprocessing directive #define
# define CONFIG_DISABLE_EXCEPTIONS 0
^~~~~~
../../../source/lib/config.h:57:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/config.h:60:2: error: invalid preprocessing directive #ifndef
#ifndef CONFIG_ENABLE_CHECKS
^~~~~~
../../../source/lib/config.h:61:3: error: invalid preprocessing directive #define
# define CONFIG_ENABLE_CHECKS 0
^~~~~~
../../../source/lib/config.h:62:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/config.h:65:2: error: invalid preprocessing directive #ifndef
#ifndef CONFIG_DEHYDRA
^~~~~~
../../../source/lib/config.h:66:3: error: invalid preprocessing directive #define
# define CONFIG_DEHYDRA 0
^~~~~~
../../../source/lib/config.h:67:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/config.h:70:2: error: invalid preprocessing directive #ifndef
#ifndef CONFIG_ENABLE_BOOST
^~~~~~
../../../source/lib/config.h:71:3: error: invalid preprocessing directive #define
# define CONFIG_ENABLE_BOOST 1
^~~~~~
../../../source/lib/config.h:72:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/config.h:74:2: error: #endif without #if
#endif // #ifndef INCLUDED_CONFIG
^~~~~
In file included from ../../../source/lib/precompiled.h:40,
from ../../../source/pch/simulation2/precompiled.h:19,
from ../../../source/simulation2/components/CCmpOverlayRenderer.cpp:18:
../../../source/lib/sysdep/compiler.h:27:2: error: invalid preprocessing directive #ifndef
#ifndef INCLUDED_COMPILER
^~~~~~
../../../source/lib/sysdep/compiler.h:28:2: error: invalid preprocessing directive #define
#define INCLUDED_COMPILER
^~~~~~
../../../source/lib/sysdep/compiler.h:34:2: error: invalid preprocessing directive #ifdef
#ifdef _MSC_VER
^~~~~
../../../source/lib/sysdep/compiler.h:35:3: error: invalid preprocessing directive #define
# define MSC_VERSION _MSC_VER
^~~~~~
../../../source/lib/sysdep/compiler.h:36:2: error: #else without #if
#else
^~~~
../../../source/lib/sysdep/compiler.h:37:3: error: invalid preprocessing directive #define
# define MSC_VERSION 0
^~~~~~
../../../source/lib/sysdep/compiler.h:38:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:40:2: error: invalid preprocessing directive #if
#if defined(__INTEL_COMPILER)
^~
../../../source/lib/sysdep/compiler.h:41:3: error: invalid preprocessing directive #define
# define ICC_VERSION __INTEL_COMPILER
^~~~~~
../../../source/lib/sysdep/compiler.h:42:2: error: #else without #if
#else
^~~~
../../../source/lib/sysdep/compiler.h:43:3: error: invalid preprocessing directive #define
# define ICC_VERSION 0
^~~~~~
../../../source/lib/sysdep/compiler.h:44:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:46:2: error: invalid preprocessing directive #if
#if defined(__LCC__) && !defined(__e2k__)
^~
../../../source/lib/sysdep/compiler.h:47:3: error: invalid preprocessing directive #define
# define LCC_VERSION __LCC__
^~~~~~
../../../source/lib/sysdep/compiler.h:48:2: error: #else without #if
#else
^~~~
../../../source/lib/sysdep/compiler.h:49:3: error: invalid preprocessing directive #define
# define LCC_VERSION 0
^~~~~~
../../../source/lib/sysdep/compiler.h:50:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:52:2: error: invalid preprocessing directive #if
#if defined(__LCC__) && defined(__e2k__)
^~
../../../source/lib/sysdep/compiler.h:53:3: error: invalid preprocessing directive #define
# define MCST_LCC_VERSION (__LCC__*100 + __LCC_MINOR__)
^~~~~~
../../../source/lib/sysdep/compiler.h:54:2: error: #else without #if
#else
^~~~
../../../source/lib/sysdep/compiler.h:55:3: error: invalid preprocessing directive #define
# define MCST_LCC_VERSION 0
^~~~~~
../../../source/lib/sysdep/compiler.h:56:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:58:2: error: invalid preprocessing directive #ifdef
#ifdef __GNUC__
^~~~~
../../../source/lib/sysdep/compiler.h:59:3: error: invalid preprocessing directive #define
# define GCC_VERSION (__GNUC__*100 + __GNUC_MINOR__)
^~~~~~
../../../source/lib/sysdep/compiler.h:60:2: error: #else without #if
#else
^~~~
../../../source/lib/sysdep/compiler.h:61:3: error: invalid preprocessing directive #define
# define GCC_VERSION 0
^~~~~~
../../../source/lib/sysdep/compiler.h:62:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:66:2: error: invalid preprocessing directive #ifdef
#ifdef __clang__
^~~~~
../../../source/lib/sysdep/compiler.h:67:3: error: invalid preprocessing directive #define
# define CLANG_VERSION (__clang_major__*100 + __clang_minor__)
^~~~~~
../../../source/lib/sysdep/compiler.h:68:2: error: #else without #if
#else
^~~~
../../../source/lib/sysdep/compiler.h:69:3: error: invalid preprocessing directive #define
# define CLANG_VERSION 0
^~~~~~
../../../source/lib/sysdep/compiler.h:70:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:73:2: error: invalid preprocessing directive #ifndef
#ifndef __has_feature
^~~~~~
../../../source/lib/sysdep/compiler.h:74:3: error: invalid preprocessing directive #define
# define __has_feature(x) 0
^~~~~~
../../../source/lib/sysdep/compiler.h:75:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:77:2: error: invalid preprocessing directive #ifndef
#ifndef __has_cpp_attribute
^~~~~~
../../../source/lib/sysdep/compiler.h:78:3: error: invalid preprocessing directive #define
# define __has_cpp_attribute(x) 0
^~~~~~
../../../source/lib/sysdep/compiler.h:79:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:95:2: error: invalid preprocessing directive #define
#define HAVE_C99 0
^~~~~~
../../../source/lib/sysdep/compiler.h:96:2: error: invalid preprocessing directive #ifdef
#ifdef __STDC_VERSION__
^~~~~
../../../source/lib/sysdep/compiler.h:97:3: error: invalid preprocessing directive #if
# if __STDC_VERSION__ >= 199901L
^~
../../../source/lib/sysdep/compiler.h:98:4: error: invalid preprocessing directive #undef
# undef HAVE_C99
^~~~~
../../../source/lib/sysdep/compiler.h:99:4: error: invalid preprocessing directive #define
# define HAVE_C99 1
^~~~~~
../../../source/lib/sysdep/compiler.h:100:3: error: #endif without #if
# endif
^~~~~
../../../source/lib/sysdep/compiler.h:101:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:106:2: error: invalid preprocessing directive #ifndef
#ifndef COMPILER_HAS_SSE
^~~~~~
../../../source/lib/sysdep/compiler.h:107:3: error: invalid preprocessing directive #if
# if GCC_VERSION && defined(__SSE__)
^~
../../../source/lib/sysdep/compiler.h:108:4: error: invalid preprocessing directive #define
# define COMPILER_HAS_SSE 1
^~~~~~
../../../source/lib/sysdep/compiler.h:109:3: error: invalid preprocessing directive #elif
# elif MSC_VERSION // also includes ICC
^~~~
../../../source/lib/sysdep/compiler.h:110:4: error: invalid preprocessing directive #define
# define COMPILER_HAS_SSE 1
^~~~~~
../../../source/lib/sysdep/compiler.h:111:3: error: #else without #if
# else
^~~~
../../../source/lib/sysdep/compiler.h:112:4: error: invalid preprocessing directive #define
# define COMPILER_HAS_SSE 0
^~~~~~
../../../source/lib/sysdep/compiler.h:113:3: error: #endif without #if
# endif
^~~~~
../../../source/lib/sysdep/compiler.h:114:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:116:2: error: invalid preprocessing directive #ifndef
#ifndef COMPILER_HAS_SSE2
^~~~~~
../../../source/lib/sysdep/compiler.h:117:3: error: invalid preprocessing directive #if
# if GCC_VERSION && defined(__SSE2__)
^~
../../../source/lib/sysdep/compiler.h:118:4: error: invalid preprocessing directive #define
# define COMPILER_HAS_SSE2 1
^~~~~~
../../../source/lib/sysdep/compiler.h:119:3: error: invalid preprocessing directive #elif
# elif MSC_VERSION // also includes ICC
^~~~
../../../source/lib/sysdep/compiler.h:120:4: error: invalid preprocessing directive #define
# define COMPILER_HAS_SSE2 1
^~~~~~
../../../source/lib/sysdep/compiler.h:121:3: error: #else without #if
# else
^~~~
../../../source/lib/sysdep/compiler.h:122:4: error: invalid preprocessing directive #define
# define COMPILER_HAS_SSE2 0
^~~~~~
../../../source/lib/sysdep/compiler.h:123:3: error: #endif without #if
# endif
^~~~~
../../../source/lib/sysdep/compiler.h:124:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:126:2: error: #endif without #if
#endif // #ifndef INCLUDED_COMPILER
^~~~~
In file included from ../../../source/pch/simulation2/precompiled.h:19,
from ../../../source/simulation2/components/CCmpOverlayRenderer.cpp:18:
../../../source/lib/precompiled.h:43:2: error: invalid preprocessing directive #if
#if MSC_VERSION
^~
../../../source/lib/precompiled.h:44:3: error: invalid preprocessing directive #if
# if MSC_VERSION < 1910
^~
../../../source/lib/precompiled.h:45:5: error: #error "Visual Studio 2017 is the minimal supported version"
# error "Visual Studio 2017 is the minimal supported version"
^~~~~
../../../source/lib/precompiled.h:46:3: error: #endif without #if
# endif
^~~~~
../../../source/lib/precompiled.h:47:3: error: invalid preprocessing directive #ifdef
# ifdef NDEBUG // release: disable all checks
^~~~~
../../../source/lib/precompiled.h:48:4: error: invalid preprocessing directive #define
# define _HAS_ITERATOR_DEBUGGING 0
^~~~~~
../../../source/lib/precompiled.h:49:4: error: invalid preprocessing directive #define
# define _SECURE_SCL 0
^~~~~~
../../../source/lib/precompiled.h:50:3: error: #endif without #if
# endif
^~~~~
../../../source/lib/precompiled.h:51:2: error: #endif without #if
#endif
^~~~~
In file included from ../../../source/lib/precompiled.h:55,
from ../../../source/pch/simulation2/precompiled.h:19,
from ../../../source/simulation2/components/CCmpOverlayRenderer.cpp:18:
../../../source/lib/pch/pch_warnings.h:23:2: error: invalid preprocessing directive #ifndef
#ifndef INCLUDED_PCH_WARNINGS
^~~~~~
../../../source/lib/pch/pch_warnings.h:24:2: error: invalid preprocessing directive #define
#define INCLUDED_PCH_WARNINGS
^~~~~~
In file included from ../../../source/lib/pch/pch_warnings.h:26,
from ../../../source/lib/precompiled.h:55,
from ../../../source/pch/simulation2/precompiled.h:19,
from ../../../source/simulation2/components/CCmpOverlayRenderer.cpp:18:
../../../source/lib/sysdep/compiler.h:27:2: error: invalid preprocessing directive #ifndef
#ifndef INCLUDED_COMPILER
^~~~~~
../../../source/lib/sysdep/compiler.h:28:2: error: invalid preprocessing directive #define
#define INCLUDED_COMPILER
^~~~~~
../../../source/lib/sysdep/compiler.h:34:2: error: invalid preprocessing directive #ifdef
#ifdef _MSC_VER
^~~~~
../../../source/lib/sysdep/compiler.h:35:3: error: invalid preprocessing directive #define
# define MSC_VERSION _MSC_VER
^~~~~~
../../../source/lib/sysdep/compiler.h:36:2: error: #else without #if
#else
^~~~
../../../source/lib/sysdep/compiler.h:37:3: error: invalid preprocessing directive #define
# define MSC_VERSION 0
^~~~~~
../../../source/lib/sysdep/compiler.h:38:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:40:2: error: invalid preprocessing directive #if
#if defined(__INTEL_COMPILER)
^~
../../../source/lib/sysdep/compiler.h:41:3: error: invalid preprocessing directive #define
# define ICC_VERSION __INTEL_COMPILER
^~~~~~
../../../source/lib/sysdep/compiler.h:42:2: error: #else without #if
#else
^~~~
../../../source/lib/sysdep/compiler.h:43:3: error: invalid preprocessing directive #define
# define ICC_VERSION 0
^~~~~~
../../../source/lib/sysdep/compiler.h:44:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:46:2: error: invalid preprocessing directive #if
#if defined(__LCC__) && !defined(__e2k__)
^~
../../../source/lib/sysdep/compiler.h:47:3: error: invalid preprocessing directive #define
# define LCC_VERSION __LCC__
^~~~~~
../../../source/lib/sysdep/compiler.h:48:2: error: #else without #if
#else
^~~~
../../../source/lib/sysdep/compiler.h:49:3: error: invalid preprocessing directive #define
# define LCC_VERSION 0
^~~~~~
../../../source/lib/sysdep/compiler.h:50:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:52:2: error: invalid preprocessing directive #if
#if defined(__LCC__) && defined(__e2k__)
^~
../../../source/lib/sysdep/compiler.h:53:3: error: invalid preprocessing directive #define
# define MCST_LCC_VERSION (__LCC__*100 + __LCC_MINOR__)
^~~~~~
../../../source/lib/sysdep/compiler.h:54:2: error: #else without #if
#else
^~~~
../../../source/lib/sysdep/compiler.h:55:3: error: invalid preprocessing directive #define
# define MCST_LCC_VERSION 0
^~~~~~
../../../source/lib/sysdep/compiler.h:56:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:58:2: error: invalid preprocessing directive #ifdef
#ifdef __GNUC__
^~~~~
../../../source/lib/sysdep/compiler.h:59:3: error: invalid preprocessing directive #define
# define GCC_VERSION (__GNUC__*100 + __GNUC_MINOR__)
^~~~~~
../../../source/lib/sysdep/compiler.h:60:2: error: #else without #if
#else
^~~~
../../../source/lib/sysdep/compiler.h:61:3: error: invalid preprocessing directive #define
# define GCC_VERSION 0
^~~~~~
../../../source/lib/sysdep/compiler.h:62:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:66:2: error: invalid preprocessing directive #ifdef
#ifdef __clang__
^~~~~
../../../source/lib/sysdep/compiler.h:67:3: error: invalid preprocessing directive #define
# define CLANG_VERSION (__clang_major__*100 + __clang_minor__)
^~~~~~
../../../source/lib/sysdep/compiler.h:68:2: error: #else without #if
#else
^~~~
../../../source/lib/sysdep/compiler.h:69:3: error: invalid preprocessing directive #define
# define CLANG_VERSION 0
^~~~~~
../../../source/lib/sysdep/compiler.h:70:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:73:2: error: invalid preprocessing directive #ifndef
#ifndef __has_feature
^~~~~~
../../../source/lib/sysdep/compiler.h:74:3: error: invalid preprocessing directive #define
# define __has_feature(x) 0
^~~~~~
../../../source/lib/sysdep/compiler.h:75:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:77:2: error: invalid preprocessing directive #ifndef
#ifndef __has_cpp_attribute
^~~~~~
../../../source/lib/sysdep/compiler.h:78:3: error: invalid preprocessing directive #define
# define __has_cpp_attribute(x) 0
^~~~~~
../../../source/lib/sysdep/compiler.h:79:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:95:2: error: invalid preprocessing directive #define
#define HAVE_C99 0
^~~~~~
../../../source/lib/sysdep/compiler.h:96:2: error: invalid preprocessing directive #ifdef
#ifdef __STDC_VERSION__
^~~~~
../../../source/lib/sysdep/compiler.h:97:3: error: invalid preprocessing directive #if
# if __STDC_VERSION__ >= 199901L
^~
../../../source/lib/sysdep/compiler.h:98:4: error: invalid preprocessing directive #undef
# undef HAVE_C99
^~~~~
../../../source/lib/sysdep/compiler.h:99:4: error: invalid preprocessing directive #define
# define HAVE_C99 1
^~~~~~
../../../source/lib/sysdep/compiler.h:100:3: error: #endif without #if
# endif
^~~~~
../../../source/lib/sysdep/compiler.h:101:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:106:2: error: invalid preprocessing directive #ifndef
#ifndef COMPILER_HAS_SSE
^~~~~~
../../../source/lib/sysdep/compiler.h:107:3: error: invalid preprocessing directive #if
# if GCC_VERSION && defined(__SSE__)
^~
../../../source/lib/sysdep/compiler.h:108:4: error: invalid preprocessing directive #define
# define COMPILER_HAS_SSE 1
^~~~~~
../../../source/lib/sysdep/compiler.h:109:3: error: invalid preprocessing directive #elif
# elif MSC_VERSION // also includes ICC
^~~~
../../../source/lib/sysdep/compiler.h:110:4: error: invalid preprocessing directive #define
# define COMPILER_HAS_SSE 1
^~~~~~
../../../source/lib/sysdep/compiler.h:111:3: error: #else without #if
# else
^~~~
../../../source/lib/sysdep/compiler.h:112:4: error: invalid preprocessing directive #define
# define COMPILER_HAS_SSE 0
^~~~~~
../../../source/lib/sysdep/compiler.h:113:3: error: #endif without #if
# endif
^~~~~
../../../source/lib/sysdep/compiler.h:114:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:116:2: error: invalid preprocessing directive #ifndef
#ifndef COMPILER_HAS_SSE2
^~~~~~
../../../source/lib/sysdep/compiler.h:117:3: error: invalid preprocessing directive #if
# if GCC_VERSION && defined(__SSE2__)
^~
../../../source/lib/sysdep/compiler.h:118:4: error: invalid preprocessing directive #define
# define COMPILER_HAS_SSE2 1
^~~~~~
../../../source/lib/sysdep/compiler.h:119:3: error: invalid preprocessing directive #elif
# elif MSC_VERSION // also includes ICC
^~~~
../../../source/lib/sysdep/compiler.h:120:4: error: invalid preprocessing directive #define
# define COMPILER_HAS_SSE2 1
^~~~~~
../../../source/lib/sysdep/compiler.h:121:3: error: #else without #if
# else
^~~~
../../../source/lib/sysdep/compiler.h:122:4: error: invalid preprocessing directive #define
# define COMPILER_HAS_SSE2 0
^~~~~~
../../../source/lib/sysdep/compiler.h:123:3: error: #endif without #if
# endif
^~~~~
../../../source/lib/sysdep/compiler.h:124:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/sysdep/compiler.h:126:2: error: #endif without #if
#endif // #ifndef INCLUDED_COMPILER
^~~~~
In file included from ../../../source/lib/precompiled.h:55,
from ../../../source/pch/simulation2/precompiled.h:19,
from ../../../source/simulation2/components/CCmpOverlayRenderer.cpp:18:
../../../source/lib/pch/pch_warnings.h:28:2: error: invalid preprocessing directive #if
#if MSC_VERSION
^~
../../../source/lib/pch/pch_warnings.h:30:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:4201) // nameless struct (Matrix3D)
^~~~~~
../../../source/lib/pch/pch_warnings.h:31:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:4244) // conversion from uintN to uint8
^~~~~~
../../../source/lib/pch/pch_warnings.h:33:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:4103) // alignment changed after including header (boost has #pragma pack/pop in separate headers)
^~~~~~
../../../source/lib/pch/pch_warnings.h:34:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:4127) // conditional expression is constant; rationale: see STMT in lib.h.
^~~~~~
../../../source/lib/pch/pch_warnings.h:35:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:4324) // structure was padded due to __declspec(align())
^~~~~~
../../../source/lib/pch/pch_warnings.h:36:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:4574) // macro is defined to be 0
^~~~~~
../../../source/lib/pch/pch_warnings.h:37:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:4355) // 'this' used in base member initializer list
^~~~~~
../../../source/lib/pch/pch_warnings.h:38:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:4512) // assignment operator could not be generated
^~~~~~
../../../source/lib/pch/pch_warnings.h:39:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:4718) // recursive call has no side effects, deleting
^~~~~~
../../../source/lib/pch/pch_warnings.h:40:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:4786) // identifier truncated to 255 chars
^~~~~~
../../../source/lib/pch/pch_warnings.h:41:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:4996) // function is deprecated
^~~~~~
../../../source/lib/pch/pch_warnings.h:42:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:6011) // dereferencing NULL pointer
^~~~~~
../../../source/lib/pch/pch_warnings.h:43:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:6246) // local declaration hides declaration of the same name in outer scope
^~~~~~
../../../source/lib/pch/pch_warnings.h:44:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:6326) // potential comparison of a constant with another constant
^~~~~~
../../../source/lib/pch/pch_warnings.h:45:3: error: invalid preprocessing directive #pragma
# pragma warning(disable:6334) // sizeof operator applied to an expression with an operator might yield unexpected results
^~~~~~
../../../source/lib/pch/pch_warnings.h:47:3: error: invalid preprocessing directive #if
# if ICC_VERSION
^~
../../../source/lib/pch/pch_warnings.h:48:4: error: invalid preprocessing directive #pragma
# pragma warning(disable:383) // value copied to temporary, reference to temporary used
^~~~~~
../../../source/lib/pch/pch_warnings.h:49:4: error: invalid preprocessing directive #pragma
# pragma warning(disable:981) // operands are evaluated in unspecified order
^~~~~~
../../../source/lib/pch/pch_warnings.h:50:4: error: invalid preprocessing directive #pragma
# pragma warning(disable:1418) // external function definition with no prior declaration (raised for all non-static function templates)
^~~~~~
In file included from ../../../source/lib/precompiled.h:55,
from ../../../source/pch/simulation2/precompiled.h:19,
from ../../../source/simulation2/components/CCmpOverlayRenderer.cpp:18:
../../../source/lib/pch/pch_warnings.h:51:4: error: invalid preprocessing directive #pragma
# pragma warning(disable:1572) // floating-point equality and inequality comparisons are unreliable
^~~~~~
../../../source/lib/pch/pch_warnings.h:52:4: error: invalid preprocessing directive #pragma
# pragma warning(disable:1684) // conversion from pointer to same-sized integral type
^~~~~~
../../../source/lib/pch/pch_warnings.h:53:4: error: invalid preprocessing directive #pragma
# pragma warning(disable:1786) // function is deprecated (disabling 4996 isn't sufficient)
^~~~~~
../../../source/lib/pch/pch_warnings.h:54:4: error: invalid preprocessing directive #pragma
# pragma warning(disable:2415) // variable of static storage duration was declared but never referenced (raised by Boost)
^~~~~~
../../../source/lib/pch/pch_warnings.h:55:3: error: #endif without #if
# endif
^~~~~
../../../source/lib/pch/pch_warnings.h:57:3: error: invalid preprocessing directive #pragma
# pragma warning(default:4062) // enumerator is not handled
^~~~~~
../../../source/lib/pch/pch_warnings.h:58:3: error: invalid preprocessing directive #pragma
# pragma warning(default:4254) // [bit field] conversion, possible loss of data
^~~~~~
../../../source/lib/pch/pch_warnings.h:59:3: error: invalid preprocessing directive #pragma
# pragma warning(default:4265) // class has virtual functions, but destructor is not virtual
^~~~~~
../../../source/lib/pch/pch_warnings.h:60:3: error: invalid preprocessing directive #pragma
# pragma warning(default:4296) // [unsigned comparison vs. 0 =>] expression is always false
^~~~~~
../../../source/lib/pch/pch_warnings.h:61:3: error: invalid preprocessing directive #pragma
# pragma warning(default:4545 4546 4547 4549) // ill-formed comma expressions; exclude 4548 since _SECURE_SCL triggers it frequently
^~~~~~
../../../source/lib/pch/pch_warnings.h:62:3: error: invalid preprocessing directive #pragma
# pragma warning(default:4557) // __assume contains effect
^~~~~~
../../../source/lib/pch/pch_warnings.h:64:3: error: invalid preprocessing directive #pragma
# pragma warning(default:4905) // wide string literal cast to LPSTR
^~~~~~
../../../source/lib/pch/pch_warnings.h:65:3: error: invalid preprocessing directive #pragma
# pragma warning(default:4906) // string literal cast to LPWSTR
^~~~~~
../../../source/lib/pch/pch_warnings.h:66:3: error: invalid preprocessing directive #pragma
# pragma warning(default:4928) // illegal copy-initialization; more than one user-defined conversion has been implicitly applied
^~~~~~
../../../source/lib/pch/pch_warnings.h:67:3: error: invalid preprocessing directive #pragma
# pragma warning(default:4946) // reinterpret_cast used between related classes
^~~~~~
../../../source/lib/pch/pch_warnings.h:74:2: error: #endif without #if
#endif
^~~~~
../../../source/lib/pch/pch_warnings.h:76:2: error: #endif without #if
#endif // #ifndef INCLUDED_PCH_WARNINGS
^~~~~
In file included from ../../../source/pch/simulation2/precompiled.h:19,
from ../../../source/simulation2/components/CCmpOverlayRenderer.cpp:18:
../../../source/lib/precompiled.h:57:2: error: invalid preprocessing directive #if
#if ICC_VERSION
^~
../../../source/lib/precompiled.h:58:10: fatal error: mathimf.h: No such file or directory
#include <mathimf.h> // (must come before <cmath> or <math.h> (replaces them))
^~~~~~~~~~~
compilation terminated.
make[1]: *** [simulation2.make:275: obj/simulation2_Debug/CCmpOverlayRenderer.o] Error 1
make: *** [Makefile:107: simulation2] Error 2Link to build: https://jenkins.wildfiregames.com/job/docker-differential/4346/display/redirect
Comment Actions
In file included from ../../../source/maths/tests/test_Matrix3d.cpp:17:
source/maths/tests/test_Matrix3d.h: In member function ‘void TestMatrix::test_MatrixMultiplicationPerformance()’:
source/maths/tests/test_Matrix3d.h:85:21: warning: comparison of integer expressions of different signedness: ‘int’ and ‘const size_t’ {aka ‘const long unsigned int’} [-Wsign-compare]
85 | for (int i = 0; i < number_of_iteration; ++i)
| ~~^~~~~~~~~~~~~~~~~~~~~
source/maths/tests/test_Matrix3d.h: In member function ‘void TestMatrix::test_MatrixBlendPerformance()’:
source/maths/tests/test_Matrix3d.h:161:21: warning: comparison of integer expressions of different signedness: ‘int’ and ‘const size_t’ {aka ‘const long unsigned int’} [-Wsign-compare]
161 | for (int i = 0; i < number_of_iteration; ++i)
| ~~^~~~~~~~~~~~~~~~~~~~~
source/maths/tests/test_Matrix3d.h: In member function ‘void TestMatrix::test_MatrixAddBlendPerformance()’:
source/maths/tests/test_Matrix3d.h:232:21: warning: comparison of integer expressions of different signedness: ‘int’ and ‘const size_t’ {aka ‘const long unsigned int’} [-Wsign-compare]
232 | for (int i = 0; i < number_of_iteration; ++i)
| ~~^~~~~~~~~~~~~~~~~~~~~Test result on Intel Xeon E3-1231 v3 on Linux:
matrix multiplication number_of_samples = 200 number_of_iteration = 1000000 have_sse = true SSE (off): 3.31916ms SSE (on): 3.45753ms . matrix Blend number_of_samples = 200 number_of_iteration = 1000000 have_sse = true SSE (off): 0.578142ms SSE (on): 0.612975ms . matrix AddBlend number_of_samples = 200 number_of_iteration = 1000000 have_sse = true SSE (off): 0.623511ms SSE (on): 0.572878ms

Comment Actions
Fix warnings, remove auto, fix ARB shaders by using pointers.
matrix multiplication number_of_samples = 200 number_of_iteration = 1000000 have_sse = true SSE (off): 4.08473ms SSE (on): 2.32536ms matrix Blend number_of_samples = 200 number_of_iteration = 1000000 have_sse = true SSE (off): 2.53577ms SSE (on): 2.54795ms matrix AddBlend number_of_samples = 200 number_of_iteration = 1000000 have_sse = true SSE (off): 2.58609ms SSE (on): 2.6201ms
Comment Actions
Successful build - Chance fights ever on the side of the prudent.
builderr-release-gcc7.txt
In file included from ../../../source/pch/atlas/precompiled.h:26:
../../../source/tools/atlas/GameInterface/Messages.h: In function 'void AtlasMessage::fGetTerrainGroupPreviews(AtlasMessage::qGetTerrainGroupPreviews*)':
../../../source/tools/atlas/GameInterface/Messages.h:315:8: warning: '#'target_mem_ref' not supported by dump_expr#<expression error>' may be used uninitialized in this function [-Wmaybe-uninitialized]
struct sTerrainTexturePreview
^~~~~~~~~~~~~~~~~~~~~~
../../../source/tools/atlas/GameInterface/Messages.h:315:8: warning: '#'target_mem_ref' not supported by dump_expr#<expression error>' may be used uninitialized in this function [-Wmaybe-uninitialized]
../../../source/tools/atlas/GameInterface/Messages.h:315:8: warning: '#'target_mem_ref' not supported by dump_expr#<expression error>' may be used uninitialized in this function [-Wmaybe-uninitialized]
../../../source/tools/atlas/GameInterface/Messages.h:315:8: warning: '#'target_mem_ref' not supported by dump_expr#<expression error>' may be used uninitialized in this function [-Wmaybe-uninitialized]
struct sTerrainTexturePreview
^~~~~~~~~~~~~~~~~~~~~~
../../../source/tools/atlas/GameInterface/Messages.h:315:8: warning: '#'target_mem_ref' not supported by dump_expr#<expression error>' may be used uninitialized in this function [-Wmaybe-uninitialized]
../../../source/tools/atlas/GameInterface/Messages.h:315:8: warning: '#'target_mem_ref' not supported by dump_expr#<expression error>' may be used uninitialized in this function [-Wmaybe-uninitialized]Link to build: https://jenkins.wildfiregames.com/job/docker-differential/4352/display/redirect
Comment Actions
Fixed graphical issue.
But dramatically increased test calculation time:
matrix multiplication number_of_samples = 200 number_of_iteration = 1000000 have_sse = true SSE (off): 3.28038ms SSE (on): 3.36736ms . matrix Blend number_of_samples = 200 number_of_iteration = 1000000 have_sse = true SSE (off): 2.49736ms SSE (on): 2.40249ms . matrix AddBlend number_of_samples = 200 number_of_iteration = 1000000 have_sse = true SSE (off): 2.36652ms SSE (on): 2.39413ms
Comment Actions
Build was aborted.
builderr-debug-macos.txt
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libnetwork_dbg.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libtinygettext_dbg.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libtinygettext_dbg.a(tinygettext.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/liblobby_dbg.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libglooxwrapper_dbg.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libsimulation2_dbg.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libscriptinterface_dbg.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libengine_dbg.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libgraphics_dbg.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libatlas_dbg.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libgui_dbg.a(precompiled.o) has no symbols
ld: warning: text-based stub file /System/Library/Frameworks//CoreAudio.framework/CoreAudio.tbd and library file /System/Library/Frameworks//CoreAudio.framework/CoreAudio are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//AudioToolbox.framework/AudioToolbox.tbd and library file /System/Library/Frameworks//AudioToolbox.framework/AudioToolbox are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ForceFeedback.framework/ForceFeedback.tbd and library file /System/Library/Frameworks//ForceFeedback.framework/ForceFeedback are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreVideo.framework/CoreVideo.tbd and library file /System/Library/Frameworks//CoreVideo.framework/CoreVideo are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Cocoa.framework/Cocoa.tbd and library file /System/Library/Frameworks//Cocoa.framework/Cocoa are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//IOKit.framework/IOKit.tbd and library file /System/Library/Frameworks//IOKit.framework/IOKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//QuartzCore.framework/QuartzCore.tbd and library file /System/Library/Frameworks//QuartzCore.framework/QuartzCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Metal.framework/Metal.tbd and library file /System/Library/Frameworks//Metal.framework/Metal are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//OpenGL.framework/OpenGL.tbd and library file /System/Library/Frameworks//OpenGL.framework/OpenGL are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Security.framework/Security.tbd and library file /System/Library/Frameworks//Security.framework/Security are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//OpenAL.framework/OpenAL.tbd and library file /System/Library/Frameworks//OpenAL.framework/OpenAL are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ApplicationServices.framework/ApplicationServices.tbd and library file /System/Library/Frameworks//ApplicationServices.framework/ApplicationServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Cocoa.framework/Cocoa.tbd and library file /System/Library/Frameworks//Cocoa.framework/Cocoa are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation.tbd and library file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//AppKit.framework/Versions/C/AppKit.tbd and library file /System/Library/Frameworks//AppKit.framework/Versions/C/AppKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreData.framework/Versions/A/CoreData.tbd and library file /System/Library/Frameworks//CoreData.framework/Versions/A/CoreData are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/CommonPanels.framework/Versions/A/CommonPanels.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/CommonPanels.framework/Versions/A/CommonPanels are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/HIToolbox.framework/Versions/A/HIToolbox.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/HIToolbox.framework/Versions/A/HIToolbox are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Help.framework/Versions/A/Help.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Help.framework/Versions/A/Help are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/ImageCapture.framework/Versions/A/ImageCapture.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/ImageCapture.framework/Versions/A/ImageCapture are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Ink.framework/Versions/A/Ink.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Ink.framework/Versions/A/Ink are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/OpenScripting.framework/Versions/A/OpenScripting.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/OpenScripting.framework/Versions/A/OpenScripting are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Print.framework/Versions/A/Print.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Print.framework/Versions/A/Print are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SecurityHI.framework/Versions/A/SecurityHI.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SecurityHI.framework/Versions/A/SecurityHI are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SpeechRecognition.framework/Versions/A/SpeechRecognition.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SpeechRecognition.framework/Versions/A/SpeechRecognition are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreImage.framework/Versions/A/CoreImage.tbd and library file /System/Library/Frameworks//CoreImage.framework/Versions/A/CoreImage are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreGraphics.framework/Versions/A/CoreGraphics.tbd and library file /System/Library/Frameworks//CoreGraphics.framework/Versions/A/CoreGraphics are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreText.framework/Versions/A/CoreText.tbd and library file /System/Library/Frameworks//CoreText.framework/Versions/A/CoreText are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ImageIO.framework/Versions/A/ImageIO.tbd and library file /System/Library/Frameworks//ImageIO.framework/Versions/A/ImageIO are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ColorSync.framework/Versions/A/ColorSync.tbd and library file /System/Library/Frameworks//ColorSync.framework/Versions/A/ColorSync are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/ATS.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/ATS are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ColorSyncLegacy.framework/Versions/A/ColorSyncLegacy.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ColorSyncLegacy.framework/Versions/A/ColorSyncLegacy are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreServices.framework/Versions/A/CoreServices.tbd and library file /System/Library/Frameworks//CoreServices.framework/Versions/A/CoreServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/HIServices.framework/Versions/A/HIServices.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/HIServices.framework/Versions/A/HIServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/LangAnalysis.framework/Versions/A/LangAnalysis.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/LangAnalysis.framework/Versions/A/LangAnalysis are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/PrintCore.framework/Versions/A/PrintCore.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/PrintCore.framework/Versions/A/PrintCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/QD.framework/Versions/A/QD.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/QD.framework/Versions/A/QD are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/SpeechSynthesis.framework/Versions/A/SpeechSynthesis.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/SpeechSynthesis.framework/Versions/A/SpeechSynthesis are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGLU.tbd and library file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGLU.dylib are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGL.tbd and library file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGL.dylib are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/PrivateFrameworks/UIFoundation.framework/Versions/A/UIFoundation.tbd and library file /System/Library/PrivateFrameworks/UIFoundation.framework/Versions/A/UIFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Foundation.framework/Versions/C/Foundation.tbd and library file /System/Library/Frameworks//Foundation.framework/Versions/C/Foundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CFNetwork.framework/Versions/A/CFNetwork.tbd and library file /System/Library/Frameworks//CFNetwork.framework/Versions/A/CFNetwork are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/FSEvents.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/FSEvents are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/CarbonCore.framework/Versions/A/CarbonCore.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/CarbonCore.framework/Versions/A/CarbonCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/Metadata.framework/Versions/A/Metadata.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/Metadata.framework/Versions/A/Metadata are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/OSServices.framework/Versions/A/OSServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/OSServices.framework/Versions/A/OSServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SearchKit.framework/Versions/A/SearchKit.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SearchKit.framework/Versions/A/SearchKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/AE.framework/Versions/A/AE.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/AE.framework/Versions/A/AE are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/LaunchServices.framework/Versions/A/LaunchServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/LaunchServices.framework/Versions/A/LaunchServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/DictionaryServices.framework/Versions/A/DictionaryServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/DictionaryServices.framework/Versions/A/DictionaryServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SharedFileList.framework/Versions/A/SharedFileList.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SharedFileList.framework/Versions/A/SharedFileList are out of sync. Falling back to library file for linking.
ld: warning: object file (../../../libraries/osx/fmt/lib/libfmt.a(format.cc.o)) was built for newer OSX version (10.13) than being linked (10.12)
ld: warning: text-based stub file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation.tbd and library file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation are out of sync. Falling back to library file for linking.
In file included from ../../../source/maths/tests/test_Matrix3d.cpp:17:
/Users/wfg/Jenkins/workspace/macos-differential/source/maths/tests/test_Matrix3d.h:85:21: warning: comparison of integers of different signs: 'int' and 'const size_t' (aka 'const unsigned long') [-Wsign-compare]
for (int i = 0; i < number_of_iteration; ++i)
~ ^ ~~~~~~~~~~~~~~~~~~~
/Users/wfg/Jenkins/workspace/macos-differential/source/maths/tests/test_Matrix3d.h:161:21: warning: comparison of integers of different signs: 'int' and 'const size_t' (aka 'const unsigned long') [-Wsign-compare]
for (int i = 0; i < number_of_iteration; ++i)
~ ^ ~~~~~~~~~~~~~~~~~~~
/Users/wfg/Jenkins/workspace/macos-differential/source/maths/tests/test_Matrix3d.h:232:21: warning: comparison of integers of different signs: 'int' and 'const size_t' (aka 'const unsigned long') [-Wsign-compare]
for (int i = 0; i < number_of_iteration; ++i)
~ ^ ~~~~~~~~~~~~~~~~~~~
3 warnings generated.
ld: warning: text-based stub file /System/Library/Frameworks//CoreAudio.framework/CoreAudio.tbd and library file /System/Library/Frameworks//CoreAudio.framework/CoreAudio are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//AudioToolbox.framework/AudioToolbox.tbd and library file /System/Library/Frameworks//AudioToolbox.framework/AudioToolbox are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ForceFeedback.framework/ForceFeedback.tbd and library file /System/Library/Frameworks//ForceFeedback.framework/ForceFeedback are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreVideo.framework/CoreVideo.tbd and library file /System/Library/Frameworks//CoreVideo.framework/CoreVideo are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Cocoa.framework/Cocoa.tbd and library file /System/Library/Frameworks//Cocoa.framework/Cocoa are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//IOKit.framework/IOKit.tbd and library file /System/Library/Frameworks//IOKit.framework/IOKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//QuartzCore.framework/QuartzCore.tbd and library file /System/Library/Frameworks//QuartzCore.framework/QuartzCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Metal.framework/Metal.tbd and library file /System/Library/Frameworks//Metal.framework/Metal are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//OpenGL.framework/OpenGL.tbd and library file /System/Library/Frameworks//OpenGL.framework/OpenGL are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Security.framework/Security.tbd and library file /System/Library/Frameworks//Security.framework/Security are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//OpenAL.framework/OpenAL.tbd and library file /System/Library/Frameworks//OpenAL.framework/OpenAL are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGLU.tbd and library file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGLU.dylib are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGL.tbd and library file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGL.dylib are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//AppKit.framework/Versions/C/AppKit.tbd and library file /System/Library/Frameworks//AppKit.framework/Versions/C/AppKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreData.framework/Versions/A/CoreData.tbd and library file /System/Library/Frameworks//CoreData.framework/Versions/A/CoreData are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ApplicationServices.framework/Versions/A/ApplicationServices.tbd and library file /System/Library/Frameworks//ApplicationServices.framework/Versions/A/ApplicationServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/CommonPanels.framework/Versions/A/CommonPanels.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/CommonPanels.framework/Versions/A/CommonPanels are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/HIToolbox.framework/Versions/A/HIToolbox.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/HIToolbox.framework/Versions/A/HIToolbox are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Help.framework/Versions/A/Help.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Help.framework/Versions/A/Help are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/ImageCapture.framework/Versions/A/ImageCapture.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/ImageCapture.framework/Versions/A/ImageCapture are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Ink.framework/Versions/A/Ink.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Ink.framework/Versions/A/Ink are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/OpenScripting.framework/Versions/A/OpenScripting.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/OpenScripting.framework/Versions/A/OpenScripting are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Print.framework/Versions/A/Print.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Print.framework/Versions/A/Print are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SecurityHI.framework/Versions/A/SecurityHI.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SecurityHI.framework/Versions/A/SecurityHI are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SpeechRecognition.framework/Versions/A/SpeechRecognition.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SpeechRecognition.framework/Versions/A/SpeechRecognition are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreImage.framework/Versions/A/CoreImage.tbd and library file /System/Library/Frameworks//CoreImage.framework/Versions/A/CoreImage are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/PrivateFrameworks/UIFoundation.framework/Versions/A/UIFoundation.tbd and library file /System/Library/PrivateFrameworks/UIFoundation.framework/Versions/A/UIFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Foundation.framework/Versions/C/Foundation.tbd and library file /System/Library/Frameworks//Foundation.framework/Versions/C/Foundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreGraphics.framework/Versions/A/CoreGraphics.tbd and library file /System/Library/Frameworks//CoreGraphics.framework/Versions/A/CoreGraphics are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreText.framework/Versions/A/CoreText.tbd and library file /System/Library/Frameworks//CoreText.framework/Versions/A/CoreText are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ImageIO.framework/Versions/A/ImageIO.tbd and library file /System/Library/Frameworks//ImageIO.framework/Versions/A/ImageIO are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ColorSync.framework/Versions/A/ColorSync.tbd and library file /System/Library/Frameworks//ColorSync.framework/Versions/A/ColorSync are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/ATS.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/ATS are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ColorSyncLegacy.framework/Versions/A/ColorSyncLegacy.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ColorSyncLegacy.framework/Versions/A/ColorSyncLegacy are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreServices.framework/Versions/A/CoreServices.tbd and library file /System/Library/Frameworks//CoreServices.framework/Versions/A/CoreServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/HIServices.framework/Versions/A/HIServices.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/HIServices.framework/Versions/A/HIServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/LangAnalysis.framework/Versions/A/LangAnalysis.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/LangAnalysis.framework/Versions/A/LangAnalysis are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/PrintCore.framework/Versions/A/PrintCore.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/PrintCore.framework/Versions/A/PrintCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/QD.framework/Versions/A/QD.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/QD.framework/Versions/A/QD are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/SpeechSynthesis.framework/Versions/A/SpeechSynthesis.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/SpeechSynthesis.framework/Versions/A/SpeechSynthesis are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CFNetwork.framework/Versions/A/CFNetwork.tbd and library file /System/Library/Frameworks//CFNetwork.framework/Versions/A/CFNetwork are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/FSEvents.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/FSEvents are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/CarbonCore.framework/Versions/A/CarbonCore.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/CarbonCore.framework/Versions/A/CarbonCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/Metadata.framework/Versions/A/Metadata.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/Metadata.framework/Versions/A/Metadata are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/OSServices.framework/Versions/A/OSServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/OSServices.framework/Versions/A/OSServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SearchKit.framework/Versions/A/SearchKit.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SearchKit.framework/Versions/A/SearchKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreFoundation.framework/Versions/A/CoreFoundation.tbd and library file /System/Library/Frameworks//CoreFoundation.framework/Versions/A/CoreFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/AE.framework/Versions/A/AE.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/AE.framework/Versions/A/AE are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/LaunchServices.framework/Versions/A/LaunchServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/LaunchServices.framework/Versions/A/LaunchServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/DictionaryServices.framework/Versions/A/DictionaryServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/DictionaryServices.framework/Versions/A/DictionaryServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SharedFileList.framework/Versions/A/SharedFileList.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SharedFileList.framework/Versions/A/SharedFileList are out of sync. Falling back to library file for linking.
ld: warning: object file (../../../libraries/osx/fmt/lib/libfmt.a(format.cc.o)) was built for newer OSX version (10.13) than being linked (10.12)
ld: warning: text-based stub file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation.tbd and library file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation are out of sync. Falling back to library file for linking.Link to build: https://jenkins.wildfiregames.com/job/macos-differential/2684/display/redirect
Comment Actions
Removes the pointer switch and replaces it with a macro condition.
First, Linux loses performance by using the SSE implementation. Therefore, this implementation is now only for Windows.
Second, we lose too much performance by using pointers. We already use SSE2 flags for Windows. For this reason, the pointers have been removed and replaced by Windows + SSE macro condition.
Comment Actions
I remember the scale functions being slower?
| source/maths/Matrix3D.h | ||
|---|---|---|
| 30 | Might make more sense to include sse.h which would pull those headers. | |
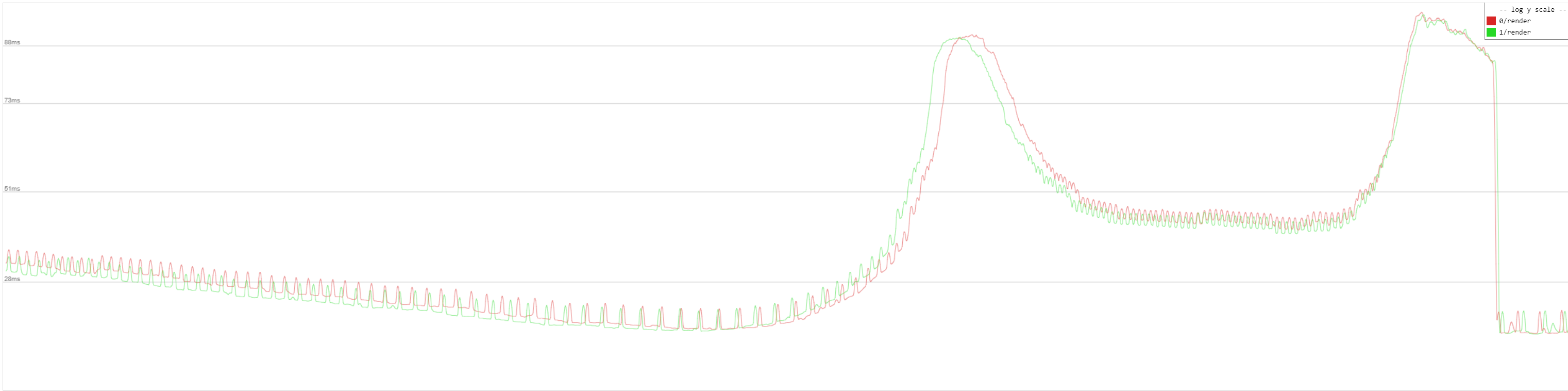
Comment Actions
Successful build - Chance fights ever on the side of the prudent.
Debug:
Microsoft (R) Build Engine version 15.9.21+g9802d43bc3 for .NET Framework
Copyright (C) Microsoft Corporation. All rights reserved.
4>MSVCRTD.lib(initializers.obj) : warning LNK4098: defaultlib 'msvcrt.lib' conflicts with use of other libs; use /NODEFAULTLIB:library [E:\Jenkins\workspace\vs2015-differential\build\workspaces\vs2017\pyrogenesis.vcxproj]
22>MSVCRTD.lib(initializers.obj) : warning LNK4098: defaultlib 'msvcrt.lib' conflicts with use of other libs; use /NODEFAULTLIB:library [E:\Jenkins\workspace\vs2015-differential\build\workspaces\vs2017\test.vcxproj]
Release:
Microsoft (R) Build Engine version 15.9.21+g9802d43bc3 for .NET Framework
Copyright (C) Microsoft Corporation. All rights reserved.Link to build: https://jenkins.wildfiregames.com/job/vs2015-differential/4260/display/redirect
Comment Actions
Successful build - Chance fights ever on the side of the prudent.
builderr-debug-macos.txt
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libsimulation2_dbg.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libengine_dbg.a(precompiled.o) has no symbols
../../../source/graphics/ShaderProgram.cpp:86:15: warning: 'Reload' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Reload()
^
../../../source/graphics/ShaderProgram.h:124:15: note: overridden virtual function is here
virtual void Reload() = 0;
^
../../../source/graphics/ShaderProgram.cpp:118:15: warning: 'Bind' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Bind()
^
../../../source/graphics/ShaderProgram.h:135:15: note: overridden virtual function is here
virtual void Bind() = 0;
^
../../../source/graphics/ShaderProgram.cpp:128:15: warning: 'Unbind' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Unbind()
^
../../../source/graphics/ShaderProgram.h:140:15: note: overridden virtual function is here
virtual void Unbind() = 0;
^
../../../source/graphics/ShaderProgram.cpp:156:18: warning: 'GetTextureBinding' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual Binding GetTextureBinding(texture_id_t id)
^
../../../source/graphics/ShaderProgram.h:149:18: note: overridden virtual function is here
virtual Binding GetTextureBinding(texture_id_t id) = 0;
^
../../../source/graphics/ShaderProgram.cpp:166:15: warning: 'BindTexture' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void BindTexture(texture_id_t id, Handle tex)
^
../../../source/graphics/ShaderProgram.h:153:15: note: overridden virtual function is here
virtual void BindTexture(texture_id_t id, Handle tex) = 0;
^
../../../source/graphics/ShaderProgram.cpp:179:15: warning: 'BindTexture' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void BindTexture(texture_id_t id, GLuint tex)
^
../../../source/graphics/ShaderProgram.h:154:15: note: overridden virtual function is here
virtual void BindTexture(texture_id_t id, GLuint tex) = 0;
^
../../../source/graphics/ShaderProgram.cpp:190:15: warning: 'BindTexture' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void BindTexture(Binding id, Handle tex)
^
../../../source/graphics/ShaderProgram.h:155:15: note: overridden virtual function is here
virtual void BindTexture(Binding id, Handle tex) = 0;
^
../../../source/graphics/ShaderProgram.cpp:197:18: warning: 'GetUniformBinding' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual Binding GetUniformBinding(uniform_id_t id)
^
../../../source/graphics/ShaderProgram.h:158:18: note: overridden virtual function is here
virtual Binding GetUniformBinding(uniform_id_t id) = 0;
^
../../../source/graphics/ShaderProgram.cpp:202:15: warning: 'Uniform' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Uniform(Binding id, float v0, float v1, float v2, float v3)
^
../../../source/graphics/ShaderProgram.h:161:15: note: overridden virtual function is here
virtual void Uniform(Binding id, float v0, float v1, float v2, float v3) = 0;
^
../../../source/graphics/ShaderProgram.cpp:211:15: warning: 'Uniform' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Uniform(Binding id, const CMatrix3D& v)
^
../../../source/graphics/ShaderProgram.h:162:15: note: overridden virtual function is here
virtual void Uniform(Binding id, const CMatrix3D& v) = 0;
^
../../../source/graphics/ShaderProgram.cpp:230:15: warning: 'Uniform' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Uniform(Binding id, size_t count, const CMatrix3D* v)
^
../../../source/graphics/ShaderProgram.h:163:15: note: overridden virtual function is here
virtual void Uniform(Binding id, size_t count, const CMatrix3D* v) = 0;
^
../../../source/graphics/ShaderProgram.cpp:236:15: warning: 'Uniform' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Uniform(Binding id, size_t count, const float* v)
^
../../../source/graphics/ShaderProgram.h:164:15: note: overridden virtual function is here
virtual void Uniform(Binding id, size_t count, const float* v) = 0;
^
12 warnings generated.
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libgraphics_dbg.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libatlas_dbg.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libgui_dbg.a(precompiled.o) has no symbols
ld: warning: text-based stub file /System/Library/Frameworks//CoreAudio.framework/CoreAudio.tbd and library file /System/Library/Frameworks//CoreAudio.framework/CoreAudio are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//AudioToolbox.framework/AudioToolbox.tbd and library file /System/Library/Frameworks//AudioToolbox.framework/AudioToolbox are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ForceFeedback.framework/ForceFeedback.tbd and library file /System/Library/Frameworks//ForceFeedback.framework/ForceFeedback are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreVideo.framework/CoreVideo.tbd and library file /System/Library/Frameworks//CoreVideo.framework/CoreVideo are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Cocoa.framework/Cocoa.tbd and library file /System/Library/Frameworks//Cocoa.framework/Cocoa are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//IOKit.framework/IOKit.tbd and library file /System/Library/Frameworks//IOKit.framework/IOKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//QuartzCore.framework/QuartzCore.tbd and library file /System/Library/Frameworks//QuartzCore.framework/QuartzCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Metal.framework/Metal.tbd and library file /System/Library/Frameworks//Metal.framework/Metal are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//OpenGL.framework/OpenGL.tbd and library file /System/Library/Frameworks//OpenGL.framework/OpenGL are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Security.framework/Security.tbd and library file /System/Library/Frameworks//Security.framework/Security are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//OpenAL.framework/OpenAL.tbd and library file /System/Library/Frameworks//OpenAL.framework/OpenAL are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ApplicationServices.framework/ApplicationServices.tbd and library file /System/Library/Frameworks//ApplicationServices.framework/ApplicationServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Cocoa.framework/Cocoa.tbd and library file /System/Library/Frameworks//Cocoa.framework/Cocoa are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation.tbd and library file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//AppKit.framework/Versions/C/AppKit.tbd and library file /System/Library/Frameworks//AppKit.framework/Versions/C/AppKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreData.framework/Versions/A/CoreData.tbd and library file /System/Library/Frameworks//CoreData.framework/Versions/A/CoreData are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/CommonPanels.framework/Versions/A/CommonPanels.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/CommonPanels.framework/Versions/A/CommonPanels are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/HIToolbox.framework/Versions/A/HIToolbox.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/HIToolbox.framework/Versions/A/HIToolbox are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Help.framework/Versions/A/Help.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Help.framework/Versions/A/Help are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/ImageCapture.framework/Versions/A/ImageCapture.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/ImageCapture.framework/Versions/A/ImageCapture are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Ink.framework/Versions/A/Ink.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Ink.framework/Versions/A/Ink are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/OpenScripting.framework/Versions/A/OpenScripting.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/OpenScripting.framework/Versions/A/OpenScripting are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Print.framework/Versions/A/Print.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Print.framework/Versions/A/Print are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SecurityHI.framework/Versions/A/SecurityHI.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SecurityHI.framework/Versions/A/SecurityHI are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SpeechRecognition.framework/Versions/A/SpeechRecognition.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SpeechRecognition.framework/Versions/A/SpeechRecognition are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreImage.framework/Versions/A/CoreImage.tbd and library file /System/Library/Frameworks//CoreImage.framework/Versions/A/CoreImage are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGLU.tbd and library file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGLU.dylib are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGL.tbd and library file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGL.dylib are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreGraphics.framework/Versions/A/CoreGraphics.tbd and library file /System/Library/Frameworks//CoreGraphics.framework/Versions/A/CoreGraphics are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreText.framework/Versions/A/CoreText.tbd and library file /System/Library/Frameworks//CoreText.framework/Versions/A/CoreText are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ImageIO.framework/Versions/A/ImageIO.tbd and library file /System/Library/Frameworks//ImageIO.framework/Versions/A/ImageIO are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ColorSync.framework/Versions/A/ColorSync.tbd and library file /System/Library/Frameworks//ColorSync.framework/Versions/A/ColorSync are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/ATS.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/ATS are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ColorSyncLegacy.framework/Versions/A/ColorSyncLegacy.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ColorSyncLegacy.framework/Versions/A/ColorSyncLegacy are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreServices.framework/Versions/A/CoreServices.tbd and library file /System/Library/Frameworks//CoreServices.framework/Versions/A/CoreServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/HIServices.framework/Versions/A/HIServices.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/HIServices.framework/Versions/A/HIServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/LangAnalysis.framework/Versions/A/LangAnalysis.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/LangAnalysis.framework/Versions/A/LangAnalysis are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/PrintCore.framework/Versions/A/PrintCore.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/PrintCore.framework/Versions/A/PrintCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/QD.framework/Versions/A/QD.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/QD.framework/Versions/A/QD are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/SpeechSynthesis.framework/Versions/A/SpeechSynthesis.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/SpeechSynthesis.framework/Versions/A/SpeechSynthesis are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/PrivateFrameworks/UIFoundation.framework/Versions/A/UIFoundation.tbd and library file /System/Library/PrivateFrameworks/UIFoundation.framework/Versions/A/UIFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Foundation.framework/Versions/C/Foundation.tbd and library file /System/Library/Frameworks//Foundation.framework/Versions/C/Foundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CFNetwork.framework/Versions/A/CFNetwork.tbd and library file /System/Library/Frameworks//CFNetwork.framework/Versions/A/CFNetwork are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/FSEvents.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/FSEvents are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/CarbonCore.framework/Versions/A/CarbonCore.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/CarbonCore.framework/Versions/A/CarbonCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/Metadata.framework/Versions/A/Metadata.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/Metadata.framework/Versions/A/Metadata are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/OSServices.framework/Versions/A/OSServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/OSServices.framework/Versions/A/OSServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SearchKit.framework/Versions/A/SearchKit.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SearchKit.framework/Versions/A/SearchKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/AE.framework/Versions/A/AE.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/AE.framework/Versions/A/AE are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/LaunchServices.framework/Versions/A/LaunchServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/LaunchServices.framework/Versions/A/LaunchServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/DictionaryServices.framework/Versions/A/DictionaryServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/DictionaryServices.framework/Versions/A/DictionaryServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SharedFileList.framework/Versions/A/SharedFileList.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SharedFileList.framework/Versions/A/SharedFileList are out of sync. Falling back to library file for linking.
ld: warning: object file (../../../libraries/osx/fmt/lib/libfmt.a(format.cc.o)) was built for newer OSX version (10.13) than being linked (10.12)
ld: warning: text-based stub file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation.tbd and library file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreAudio.framework/CoreAudio.tbd and library file /System/Library/Frameworks//CoreAudio.framework/CoreAudio are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//AudioToolbox.framework/AudioToolbox.tbd and library file /System/Library/Frameworks//AudioToolbox.framework/AudioToolbox are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ForceFeedback.framework/ForceFeedback.tbd and library file /System/Library/Frameworks//ForceFeedback.framework/ForceFeedback are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreVideo.framework/CoreVideo.tbd and library file /System/Library/Frameworks//CoreVideo.framework/CoreVideo are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Cocoa.framework/Cocoa.tbd and library file /System/Library/Frameworks//Cocoa.framework/Cocoa are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//IOKit.framework/IOKit.tbd and library file /System/Library/Frameworks//IOKit.framework/IOKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//QuartzCore.framework/QuartzCore.tbd and library file /System/Library/Frameworks//QuartzCore.framework/QuartzCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Metal.framework/Metal.tbd and library file /System/Library/Frameworks//Metal.framework/Metal are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//OpenGL.framework/OpenGL.tbd and library file /System/Library/Frameworks//OpenGL.framework/OpenGL are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Security.framework/Security.tbd and library file /System/Library/Frameworks//Security.framework/Security are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//OpenAL.framework/OpenAL.tbd and library file /System/Library/Frameworks//OpenAL.framework/OpenAL are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//AppKit.framework/Versions/C/AppKit.tbd and library file /System/Library/Frameworks//AppKit.framework/Versions/C/AppKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreData.framework/Versions/A/CoreData.tbd and library file /System/Library/Frameworks//CoreData.framework/Versions/A/CoreData are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ApplicationServices.framework/Versions/A/ApplicationServices.tbd and library file /System/Library/Frameworks//ApplicationServices.framework/Versions/A/ApplicationServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/CommonPanels.framework/Versions/A/CommonPanels.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/CommonPanels.framework/Versions/A/CommonPanels are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/HIToolbox.framework/Versions/A/HIToolbox.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/HIToolbox.framework/Versions/A/HIToolbox are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Help.framework/Versions/A/Help.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Help.framework/Versions/A/Help are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/ImageCapture.framework/Versions/A/ImageCapture.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/ImageCapture.framework/Versions/A/ImageCapture are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Ink.framework/Versions/A/Ink.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Ink.framework/Versions/A/Ink are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/OpenScripting.framework/Versions/A/OpenScripting.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/OpenScripting.framework/Versions/A/OpenScripting are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Print.framework/Versions/A/Print.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Print.framework/Versions/A/Print are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SecurityHI.framework/Versions/A/SecurityHI.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SecurityHI.framework/Versions/A/SecurityHI are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SpeechRecognition.framework/Versions/A/SpeechRecognition.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SpeechRecognition.framework/Versions/A/SpeechRecognition are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreImage.framework/Versions/A/CoreImage.tbd and library file /System/Library/Frameworks//CoreImage.framework/Versions/A/CoreImage are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGLU.tbd and library file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGLU.dylib are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGL.tbd and library file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGL.dylib are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreGraphics.framework/Versions/A/CoreGraphics.tbd and library file /System/Library/Frameworks//CoreGraphics.framework/Versions/A/CoreGraphics are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreText.framework/Versions/A/CoreText.tbd and library file /System/Library/Frameworks//CoreText.framework/Versions/A/CoreText are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ImageIO.framework/Versions/A/ImageIO.tbd and library file /System/Library/Frameworks//ImageIO.framework/Versions/A/ImageIO are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ColorSync.framework/Versions/A/ColorSync.tbd and library file /System/Library/Frameworks//ColorSync.framework/Versions/A/ColorSync are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/ATS.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/ATS are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ColorSyncLegacy.framework/Versions/A/ColorSyncLegacy.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ColorSyncLegacy.framework/Versions/A/ColorSyncLegacy are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreServices.framework/Versions/A/CoreServices.tbd and library file /System/Library/Frameworks//CoreServices.framework/Versions/A/CoreServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/HIServices.framework/Versions/A/HIServices.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/HIServices.framework/Versions/A/HIServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/LangAnalysis.framework/Versions/A/LangAnalysis.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/LangAnalysis.framework/Versions/A/LangAnalysis are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/PrintCore.framework/Versions/A/PrintCore.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/PrintCore.framework/Versions/A/PrintCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/QD.framework/Versions/A/QD.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/QD.framework/Versions/A/QD are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/SpeechSynthesis.framework/Versions/A/SpeechSynthesis.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/SpeechSynthesis.framework/Versions/A/SpeechSynthesis are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/PrivateFrameworks/UIFoundation.framework/Versions/A/UIFoundation.tbd and library file /System/Library/PrivateFrameworks/UIFoundation.framework/Versions/A/UIFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Foundation.framework/Versions/C/Foundation.tbd and library file /System/Library/Frameworks//Foundation.framework/Versions/C/Foundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CFNetwork.framework/Versions/A/CFNetwork.tbd and library file /System/Library/Frameworks//CFNetwork.framework/Versions/A/CFNetwork are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/FSEvents.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/FSEvents are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/CarbonCore.framework/Versions/A/CarbonCore.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/CarbonCore.framework/Versions/A/CarbonCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/Metadata.framework/Versions/A/Metadata.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/Metadata.framework/Versions/A/Metadata are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/OSServices.framework/Versions/A/OSServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/OSServices.framework/Versions/A/OSServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SearchKit.framework/Versions/A/SearchKit.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SearchKit.framework/Versions/A/SearchKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreFoundation.framework/Versions/A/CoreFoundation.tbd and library file /System/Library/Frameworks//CoreFoundation.framework/Versions/A/CoreFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/AE.framework/Versions/A/AE.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/AE.framework/Versions/A/AE are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/LaunchServices.framework/Versions/A/LaunchServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/LaunchServices.framework/Versions/A/LaunchServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/DictionaryServices.framework/Versions/A/DictionaryServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/DictionaryServices.framework/Versions/A/DictionaryServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SharedFileList.framework/Versions/A/SharedFileList.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SharedFileList.framework/Versions/A/SharedFileList are out of sync. Falling back to library file for linking.
ld: warning: object file (../../../libraries/osx/fmt/lib/libfmt.a(format.cc.o)) was built for newer OSX version (10.13) than being linked (10.12)
ld: warning: text-based stub file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation.tbd and library file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation are out of sync. Falling back to library file for linking.
builderr-release-macos.txt
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libsimulation2.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libengine.a(precompiled.o) has no symbols
../../../source/graphics/ShaderProgram.cpp:86:15: warning: 'Reload' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Reload()
^
../../../source/graphics/ShaderProgram.h:124:15: note: overridden virtual function is here
virtual void Reload() = 0;
^
../../../source/graphics/ShaderProgram.cpp:118:15: warning: 'Bind' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Bind()
^
../../../source/graphics/ShaderProgram.h:135:15: note: overridden virtual function is here
virtual void Bind() = 0;
^
../../../source/graphics/ShaderProgram.cpp:128:15: warning: 'Unbind' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Unbind()
^
../../../source/graphics/ShaderProgram.h:140:15: note: overridden virtual function is here
virtual void Unbind() = 0;
^
../../../source/graphics/ShaderProgram.cpp:156:18: warning: 'GetTextureBinding' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual Binding GetTextureBinding(texture_id_t id)
^
../../../source/graphics/ShaderProgram.h:149:18: note: overridden virtual function is here
virtual Binding GetTextureBinding(texture_id_t id) = 0;
^
../../../source/graphics/ShaderProgram.cpp:166:15: warning: 'BindTexture' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void BindTexture(texture_id_t id, Handle tex)
^
../../../source/graphics/ShaderProgram.h:153:15: note: overridden virtual function is here
virtual void BindTexture(texture_id_t id, Handle tex) = 0;
^
../../../source/graphics/ShaderProgram.cpp:179:15: warning: 'BindTexture' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void BindTexture(texture_id_t id, GLuint tex)
^
../../../source/graphics/ShaderProgram.h:154:15: note: overridden virtual function is here
virtual void BindTexture(texture_id_t id, GLuint tex) = 0;
^
../../../source/graphics/ShaderProgram.cpp:190:15: warning: 'BindTexture' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void BindTexture(Binding id, Handle tex)
^
../../../source/graphics/ShaderProgram.h:155:15: note: overridden virtual function is here
virtual void BindTexture(Binding id, Handle tex) = 0;
^
../../../source/graphics/ShaderProgram.cpp:197:18: warning: 'GetUniformBinding' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual Binding GetUniformBinding(uniform_id_t id)
^
../../../source/graphics/ShaderProgram.h:158:18: note: overridden virtual function is here
virtual Binding GetUniformBinding(uniform_id_t id) = 0;
^
../../../source/graphics/ShaderProgram.cpp:202:15: warning: 'Uniform' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Uniform(Binding id, float v0, float v1, float v2, float v3)
^
../../../source/graphics/ShaderProgram.h:161:15: note: overridden virtual function is here
virtual void Uniform(Binding id, float v0, float v1, float v2, float v3) = 0;
^
../../../source/graphics/ShaderProgram.cpp:211:15: warning: 'Uniform' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Uniform(Binding id, const CMatrix3D& v)
^
../../../source/graphics/ShaderProgram.h:162:15: note: overridden virtual function is here
virtual void Uniform(Binding id, const CMatrix3D& v) = 0;
^
../../../source/graphics/ShaderProgram.cpp:230:15: warning: 'Uniform' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Uniform(Binding id, size_t count, const CMatrix3D* v)
^
../../../source/graphics/ShaderProgram.h:163:15: note: overridden virtual function is here
virtual void Uniform(Binding id, size_t count, const CMatrix3D* v) = 0;
^
../../../source/graphics/ShaderProgram.cpp:236:15: warning: 'Uniform' overrides a member function but is not marked 'override' [-Winconsistent-missing-override]
virtual void Uniform(Binding id, size_t count, const float* v)
^
../../../source/graphics/ShaderProgram.h:164:15: note: overridden virtual function is here
virtual void Uniform(Binding id, size_t count, const float* v) = 0;
^
12 warnings generated.
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libgraphics.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libatlas.a(precompiled.o) has no symbols
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ranlib: file: ../../../binaries/system/libgui.a(precompiled.o) has no symbols
ld: warning: text-based stub file /System/Library/Frameworks//CoreAudio.framework/CoreAudio.tbd and library file /System/Library/Frameworks//CoreAudio.framework/CoreAudio are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//AudioToolbox.framework/AudioToolbox.tbd and library file /System/Library/Frameworks//AudioToolbox.framework/AudioToolbox are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ForceFeedback.framework/ForceFeedback.tbd and library file /System/Library/Frameworks//ForceFeedback.framework/ForceFeedback are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreVideo.framework/CoreVideo.tbd and library file /System/Library/Frameworks//CoreVideo.framework/CoreVideo are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Cocoa.framework/Cocoa.tbd and library file /System/Library/Frameworks//Cocoa.framework/Cocoa are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//IOKit.framework/IOKit.tbd and library file /System/Library/Frameworks//IOKit.framework/IOKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//QuartzCore.framework/QuartzCore.tbd and library file /System/Library/Frameworks//QuartzCore.framework/QuartzCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Metal.framework/Metal.tbd and library file /System/Library/Frameworks//Metal.framework/Metal are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//OpenGL.framework/OpenGL.tbd and library file /System/Library/Frameworks//OpenGL.framework/OpenGL are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Security.framework/Security.tbd and library file /System/Library/Frameworks//Security.framework/Security are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//OpenAL.framework/OpenAL.tbd and library file /System/Library/Frameworks//OpenAL.framework/OpenAL are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ApplicationServices.framework/ApplicationServices.tbd and library file /System/Library/Frameworks//ApplicationServices.framework/ApplicationServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Cocoa.framework/Cocoa.tbd and library file /System/Library/Frameworks//Cocoa.framework/Cocoa are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation.tbd and library file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGLU.tbd and library file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGLU.dylib are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGL.tbd and library file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGL.dylib are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreGraphics.framework/Versions/A/CoreGraphics.tbd and library file /System/Library/Frameworks//CoreGraphics.framework/Versions/A/CoreGraphics are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreText.framework/Versions/A/CoreText.tbd and library file /System/Library/Frameworks//CoreText.framework/Versions/A/CoreText are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ImageIO.framework/Versions/A/ImageIO.tbd and library file /System/Library/Frameworks//ImageIO.framework/Versions/A/ImageIO are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ColorSync.framework/Versions/A/ColorSync.tbd and library file /System/Library/Frameworks//ColorSync.framework/Versions/A/ColorSync are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/ATS.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/ATS are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ColorSyncLegacy.framework/Versions/A/ColorSyncLegacy.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ColorSyncLegacy.framework/Versions/A/ColorSyncLegacy are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreServices.framework/Versions/A/CoreServices.tbd and library file /System/Library/Frameworks//CoreServices.framework/Versions/A/CoreServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/HIServices.framework/Versions/A/HIServices.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/HIServices.framework/Versions/A/HIServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/LangAnalysis.framework/Versions/A/LangAnalysis.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/LangAnalysis.framework/Versions/A/LangAnalysis are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/PrintCore.framework/Versions/A/PrintCore.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/PrintCore.framework/Versions/A/PrintCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/QD.framework/Versions/A/QD.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/QD.framework/Versions/A/QD are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/SpeechSynthesis.framework/Versions/A/SpeechSynthesis.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/SpeechSynthesis.framework/Versions/A/SpeechSynthesis are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//AppKit.framework/Versions/C/AppKit.tbd and library file /System/Library/Frameworks//AppKit.framework/Versions/C/AppKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreData.framework/Versions/A/CoreData.tbd and library file /System/Library/Frameworks//CoreData.framework/Versions/A/CoreData are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/CommonPanels.framework/Versions/A/CommonPanels.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/CommonPanels.framework/Versions/A/CommonPanels are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/HIToolbox.framework/Versions/A/HIToolbox.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/HIToolbox.framework/Versions/A/HIToolbox are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Help.framework/Versions/A/Help.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Help.framework/Versions/A/Help are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/ImageCapture.framework/Versions/A/ImageCapture.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/ImageCapture.framework/Versions/A/ImageCapture are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Ink.framework/Versions/A/Ink.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Ink.framework/Versions/A/Ink are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/OpenScripting.framework/Versions/A/OpenScripting.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/OpenScripting.framework/Versions/A/OpenScripting are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Print.framework/Versions/A/Print.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Print.framework/Versions/A/Print are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SecurityHI.framework/Versions/A/SecurityHI.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SecurityHI.framework/Versions/A/SecurityHI are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SpeechRecognition.framework/Versions/A/SpeechRecognition.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SpeechRecognition.framework/Versions/A/SpeechRecognition are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreImage.framework/Versions/A/CoreImage.tbd and library file /System/Library/Frameworks//CoreImage.framework/Versions/A/CoreImage are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CFNetwork.framework/Versions/A/CFNetwork.tbd and library file /System/Library/Frameworks//CFNetwork.framework/Versions/A/CFNetwork are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/FSEvents.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/FSEvents are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/CarbonCore.framework/Versions/A/CarbonCore.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/CarbonCore.framework/Versions/A/CarbonCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/Metadata.framework/Versions/A/Metadata.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/Metadata.framework/Versions/A/Metadata are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/OSServices.framework/Versions/A/OSServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/OSServices.framework/Versions/A/OSServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SearchKit.framework/Versions/A/SearchKit.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SearchKit.framework/Versions/A/SearchKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/AE.framework/Versions/A/AE.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/AE.framework/Versions/A/AE are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/LaunchServices.framework/Versions/A/LaunchServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/LaunchServices.framework/Versions/A/LaunchServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/DictionaryServices.framework/Versions/A/DictionaryServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/DictionaryServices.framework/Versions/A/DictionaryServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SharedFileList.framework/Versions/A/SharedFileList.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SharedFileList.framework/Versions/A/SharedFileList are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/PrivateFrameworks/UIFoundation.framework/Versions/A/UIFoundation.tbd and library file /System/Library/PrivateFrameworks/UIFoundation.framework/Versions/A/UIFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Foundation.framework/Versions/C/Foundation.tbd and library file /System/Library/Frameworks//Foundation.framework/Versions/C/Foundation are out of sync. Falling back to library file for linking.
ld: warning: object file (../../../libraries/osx/fmt/lib/libfmt.a(format.cc.o)) was built for newer OSX version (10.13) than being linked (10.12)
ld: warning: text-based stub file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation.tbd and library file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreAudio.framework/CoreAudio.tbd and library file /System/Library/Frameworks//CoreAudio.framework/CoreAudio are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//AudioToolbox.framework/AudioToolbox.tbd and library file /System/Library/Frameworks//AudioToolbox.framework/AudioToolbox are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ForceFeedback.framework/ForceFeedback.tbd and library file /System/Library/Frameworks//ForceFeedback.framework/ForceFeedback are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreVideo.framework/CoreVideo.tbd and library file /System/Library/Frameworks//CoreVideo.framework/CoreVideo are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Cocoa.framework/Cocoa.tbd and library file /System/Library/Frameworks//Cocoa.framework/Cocoa are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//IOKit.framework/IOKit.tbd and library file /System/Library/Frameworks//IOKit.framework/IOKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//QuartzCore.framework/QuartzCore.tbd and library file /System/Library/Frameworks//QuartzCore.framework/QuartzCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Metal.framework/Metal.tbd and library file /System/Library/Frameworks//Metal.framework/Metal are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//OpenGL.framework/OpenGL.tbd and library file /System/Library/Frameworks//OpenGL.framework/OpenGL are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Security.framework/Security.tbd and library file /System/Library/Frameworks//Security.framework/Security are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//OpenAL.framework/OpenAL.tbd and library file /System/Library/Frameworks//OpenAL.framework/OpenAL are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//AppKit.framework/Versions/C/AppKit.tbd and library file /System/Library/Frameworks//AppKit.framework/Versions/C/AppKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreData.framework/Versions/A/CoreData.tbd and library file /System/Library/Frameworks//CoreData.framework/Versions/A/CoreData are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ApplicationServices.framework/Versions/A/ApplicationServices.tbd and library file /System/Library/Frameworks//ApplicationServices.framework/Versions/A/ApplicationServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/CommonPanels.framework/Versions/A/CommonPanels.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/CommonPanels.framework/Versions/A/CommonPanels are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/HIToolbox.framework/Versions/A/HIToolbox.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/HIToolbox.framework/Versions/A/HIToolbox are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Help.framework/Versions/A/Help.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Help.framework/Versions/A/Help are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/ImageCapture.framework/Versions/A/ImageCapture.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/ImageCapture.framework/Versions/A/ImageCapture are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Ink.framework/Versions/A/Ink.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Ink.framework/Versions/A/Ink are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/OpenScripting.framework/Versions/A/OpenScripting.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/OpenScripting.framework/Versions/A/OpenScripting are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Print.framework/Versions/A/Print.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/Print.framework/Versions/A/Print are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SecurityHI.framework/Versions/A/SecurityHI.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SecurityHI.framework/Versions/A/SecurityHI are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SpeechRecognition.framework/Versions/A/SpeechRecognition.tbd and library file /System/Library/Frameworks/Carbon.framework/Versions/A/Frameworks/SpeechRecognition.framework/Versions/A/SpeechRecognition are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreImage.framework/Versions/A/CoreImage.tbd and library file /System/Library/Frameworks//CoreImage.framework/Versions/A/CoreImage are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGLU.tbd and library file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGLU.dylib are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGL.tbd and library file /System/Library/Frameworks/OpenGL.framework/Versions/A/Libraries/libGL.dylib are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/PrivateFrameworks/UIFoundation.framework/Versions/A/UIFoundation.tbd and library file /System/Library/PrivateFrameworks/UIFoundation.framework/Versions/A/UIFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//Foundation.framework/Versions/C/Foundation.tbd and library file /System/Library/Frameworks//Foundation.framework/Versions/C/Foundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreGraphics.framework/Versions/A/CoreGraphics.tbd and library file /System/Library/Frameworks//CoreGraphics.framework/Versions/A/CoreGraphics are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreText.framework/Versions/A/CoreText.tbd and library file /System/Library/Frameworks//CoreText.framework/Versions/A/CoreText are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ImageIO.framework/Versions/A/ImageIO.tbd and library file /System/Library/Frameworks//ImageIO.framework/Versions/A/ImageIO are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//ColorSync.framework/Versions/A/ColorSync.tbd and library file /System/Library/Frameworks//ColorSync.framework/Versions/A/ColorSync are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/ATS.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ATS.framework/Versions/A/ATS are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ColorSyncLegacy.framework/Versions/A/ColorSyncLegacy.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/ColorSyncLegacy.framework/Versions/A/ColorSyncLegacy are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreServices.framework/Versions/A/CoreServices.tbd and library file /System/Library/Frameworks//CoreServices.framework/Versions/A/CoreServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/HIServices.framework/Versions/A/HIServices.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/HIServices.framework/Versions/A/HIServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/LangAnalysis.framework/Versions/A/LangAnalysis.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/LangAnalysis.framework/Versions/A/LangAnalysis are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/PrintCore.framework/Versions/A/PrintCore.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/PrintCore.framework/Versions/A/PrintCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/QD.framework/Versions/A/QD.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/QD.framework/Versions/A/QD are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/SpeechSynthesis.framework/Versions/A/SpeechSynthesis.tbd and library file /System/Library/Frameworks/ApplicationServices.framework/Versions/A/Frameworks/SpeechSynthesis.framework/Versions/A/SpeechSynthesis are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CoreFoundation.framework/Versions/A/CoreFoundation.tbd and library file /System/Library/Frameworks//CoreFoundation.framework/Versions/A/CoreFoundation are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks//CFNetwork.framework/Versions/A/CFNetwork.tbd and library file /System/Library/Frameworks//CFNetwork.framework/Versions/A/CFNetwork are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/FSEvents.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/FSEvents.framework/Versions/A/FSEvents are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/CarbonCore.framework/Versions/A/CarbonCore.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/CarbonCore.framework/Versions/A/CarbonCore are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/Metadata.framework/Versions/A/Metadata.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/Metadata.framework/Versions/A/Metadata are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/OSServices.framework/Versions/A/OSServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/OSServices.framework/Versions/A/OSServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SearchKit.framework/Versions/A/SearchKit.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SearchKit.framework/Versions/A/SearchKit are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/AE.framework/Versions/A/AE.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/AE.framework/Versions/A/AE are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/LaunchServices.framework/Versions/A/LaunchServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/LaunchServices.framework/Versions/A/LaunchServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/DictionaryServices.framework/Versions/A/DictionaryServices.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/DictionaryServices.framework/Versions/A/DictionaryServices are out of sync. Falling back to library file for linking.
ld: warning: text-based stub file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SharedFileList.framework/Versions/A/SharedFileList.tbd and library file /System/Library/Frameworks/CoreServices.framework/Versions/A/Frameworks/SharedFileList.framework/Versions/A/SharedFileList are out of sync. Falling back to library file for linking.
ld: warning: object file (../../../libraries/osx/fmt/lib/libfmt.a(format.cc.o)) was built for newer OSX version (10.13) than being linked (10.12)
ld: warning: text-based stub file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation.tbd and library file /System/Library/Frameworks//CoreFoundation.framework/CoreFoundation are out of sync. Falling back to library file for linking.Link to build: https://jenkins.wildfiregames.com/job/macos-differential/3160/display/redirect
Comment Actions
Successful build - Chance fights ever on the side of the prudent.
builderr-release-gcc7.txt
In file included from ../../../source/pch/atlas/precompiled.h:26:
../../../source/tools/atlas/GameInterface/Messages.h: In function 'void AtlasMessage::fGetTerrainGroupPreviews(AtlasMessage::qGetTerrainGroupPreviews*)':
../../../source/tools/atlas/GameInterface/Messages.h:315:8: warning: '#'target_mem_ref' not supported by dump_expr#<expression error>' may be used uninitialized in this function [-Wmaybe-uninitialized]
struct sTerrainTexturePreview
^~~~~~~~~~~~~~~~~~~~~~
../../../source/tools/atlas/GameInterface/Messages.h:315:8: warning: '#'target_mem_ref' not supported by dump_expr#<expression error>' may be used uninitialized in this function [-Wmaybe-uninitialized]
../../../source/tools/atlas/GameInterface/Messages.h:315:8: warning: '#'target_mem_ref' not supported by dump_expr#<expression error>' may be used uninitialized in this function [-Wmaybe-uninitialized]
../../../source/tools/atlas/GameInterface/Messages.h:315:8: warning: '#'target_mem_ref' not supported by dump_expr#<expression error>' may be used uninitialized in this function [-Wmaybe-uninitialized]
struct sTerrainTexturePreview
^~~~~~~~~~~~~~~~~~~~~~
../../../source/tools/atlas/GameInterface/Messages.h:315:8: warning: '#'target_mem_ref' not supported by dump_expr#<expression error>' may be used uninitialized in this function [-Wmaybe-uninitialized]
../../../source/tools/atlas/GameInterface/Messages.h:315:8: warning: '#'target_mem_ref' not supported by dump_expr#<expression error>' may be used uninitialized in this function [-Wmaybe-uninitialized]Link to build: https://jenkins.wildfiregames.com/job/docker-differential/4818/display/redirect