This is a bit of a paradigm change, and step 0 if that paradigm change goes through.
The core idea is to 'unprepare' the AI to run threaded, and simply run it alongside the simulation, in the same JS Compartment so that data can be readily shared.
Background
The AI is intended to be run in a separate thread, to avoid slowing the simulation down. As such, it has its own copy of the simulation data to work with, provided through AIProxy (one per entity), and AIInterface (system - also used by RL interface).
This design is not working.
There are several issues:
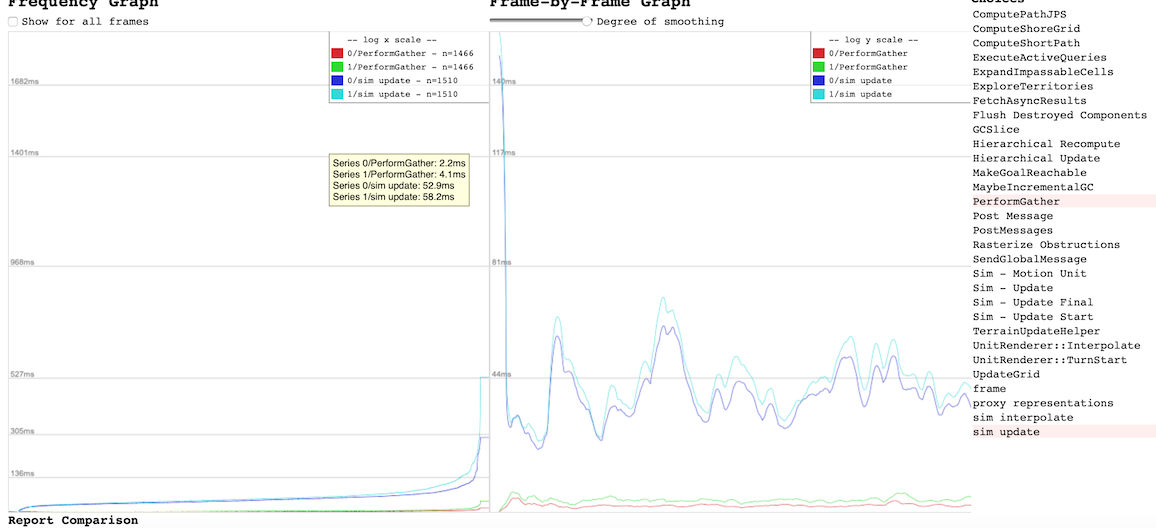
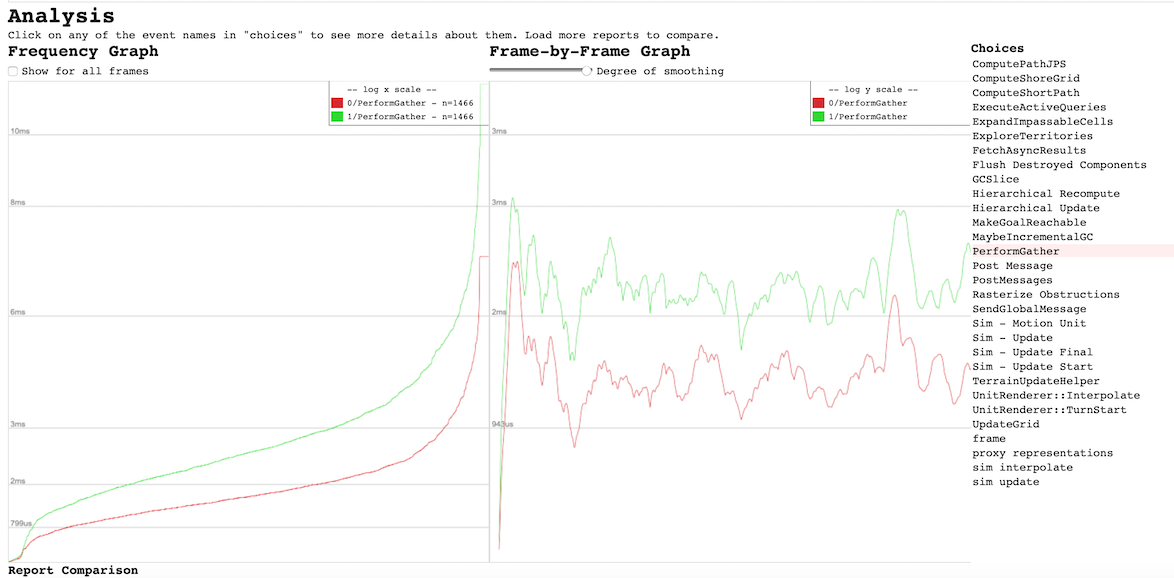
- Copying the data is actually slow on the simulation side (where threading the AI would have no impact). AIProxy & AIInterface must greedily listen to a lot of messages, and this slows every code that sends these messages down. Resource gathering for example could be around 20% faster if the AI wasn't listening to messages (see #5962 & e.g. D9).
- Relatedly, these components exist even in games without AI, which slow down MP play too (again, see D9).
- Copying the data is difficult. Technologies are a mess. We basically have to implement everything twice in a subtly different format.
- We haven't even bothered in some cases, such as LOS data. LOS is currently inaccessible to the AI. Adding it would be difficult.
- The logic was partly that the AI could not change the simulation, but that proves to be a non-issue: the AI is deterministic as is the simulation, thus any 'cheat via API' would OOS.
- On the other hand, actually cheating in the AI is difficult as it cannot change the simulation, only send commands (which all players share). This is e.g. why the gather bonus is the only real bonus the harder AIs get.
None of these issues can easily be solved as they are all integral to the design.
See also:
- A 2013 thread by Yves: https://wildfiregames.com/forum/topic/17935-ai-interface-design/
- A 2019 thread by myself: https://wildfiregames.com/forum/topic/25887-a-proposal-for-a-complete-rethinking-of-the-ai-implementation/
- #2370
What do we lose
The current design still has (or would have, once actually threaded) some advantages:
- AI computations would be threaded, thus not taking time from the simulation to run complicated calculations. Note that threading per-AI would possibly compound the problems above, however.
- Cannot change the sim.
- AI can easily use its custom format for some data.
- The AI running is likely to be slower because it will actually call stuff instead of just looking at essentially 'cached' data.
- The AI will run in the same GC zone as the simulation, meaning we can't GC one without GC-ing the other as well.
However, we could still run some calculations in a threaded manner by implementing a "worker pool", similar to web workers, and only copying the relevant data there (being careful to run this in N turns only). This would be more flexible, and give us most of the advantages.
The AI running slower is an issue, but I think the simulation gains are liable to mostly compensate the effect, and in MP it's a net gain.
Why wasn't this done before?
Part of the problem is that the AI uses its own global, its own functions, its own stuff, basically. Having both the AI & the simulation in the same JS environment is tricky, as you might get confused which function is available or not.
Or it _was_, until Spidermonkey split Realms and Compartments (which IIRC is SM68).
Nowadays, we can have two different Realms (i.e. a 'js environment' with its globals) in the same 'Compartment' (essentially a security layer), and data can be freely shared between these Realms.
This allows us to simply access the simulation from the AI without encurring a "cross compartment wrapper" perf penalty (as we would have in the past, see Yves' thread), and also without polluting the Simulation environment (in fact, the simulation still has no native way to access the AI realm).
How to implement this
It's actually quite simple, thanks to the realm split. We can run both in the same compartment, and expose the Sim and the sim 'Engine' as respectively, 'Sim' and 'SimEngine', and just call that from the AI. I chose this approach to make it obvious when the simulation is being called.
The change from copying data to calling the simulation directly can be done gradually, and I do it here for resources as an example.
Other notes
- I suspect we might actually see a lot of gain in the garbage collector, as we're likely to create fewer temporary objects.
- This impacts the RL interface directly, since the 'gamestate' it uses is the AI Interface's. I think that's mostly fine: there is now a possibility to "Evaluate" JS code from the RL Interface, and as such the python code could ask for a specific gamestate tailored to its needs, with all the required data.
- This makes it possible to cheat as much as wanted with the AI by actively modifying the simulation. I think that's actually somewhat convenient.