
User Details
- User Since
- Feb 24 2017, 5:41 PM (387 w, 10 h)
Dec 5 2021
Changed the maximum to 360 as current top end monitors support 360Hz.
Feb 27 2021
I'm not sure
Y axis: Is this the total render+simulation+gui+etc?
Yep.
If you want to see a difference you must split for each category, in the case for this diff the improvements are in the render category. I kind of see a difference between the two but don't look much diferent which means that all the noise from the other categories are drowning the render values. I tested this with the in-game profiler with AutoCiv mod corpse limit implementation so I can guarantee that there is a big improvement. In the case you are still not sold on it :) you can do a fast test with autociv (a23 or a24, doesn't matter) and compare, no even need for profiling as it very obvious.
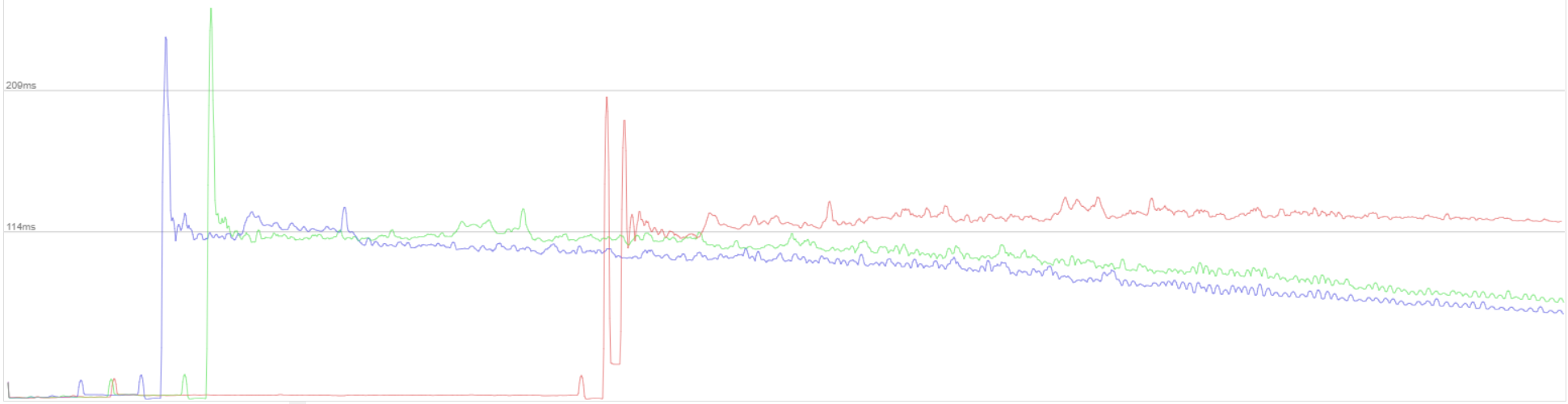
Renderer: Red vanilla, green 100, blue 50
I made a new battle profile map and profiled it.

Vanilla

Limited to 100 corpses

Limited to 50 corpses
(D3554 is needed)
Feb 19 2021
Feb 18 2021
Patch works for me, can't reproduce the bug anymore. Thx
Feb 14 2021


Adding triggers for start, save and stop recording. Shorting the cinematic path.
Feb 13 2021
Apply Imarok's comment.
Adding a new version only for testing. Work in progress.
The functionality can be tested, running the attached map.
Feb 10 2021
Feb 7 2021
Ryzen 3700X, Radeon 5700, Windows 10

red vanilla, green patched
I take the map from D3505, profil start at 2s end at 120s. The big offset is surprising me, as I start profiling after loading the map.
Feb 5 2021
I take the map from D3505, profil start at 2s end at 120s.
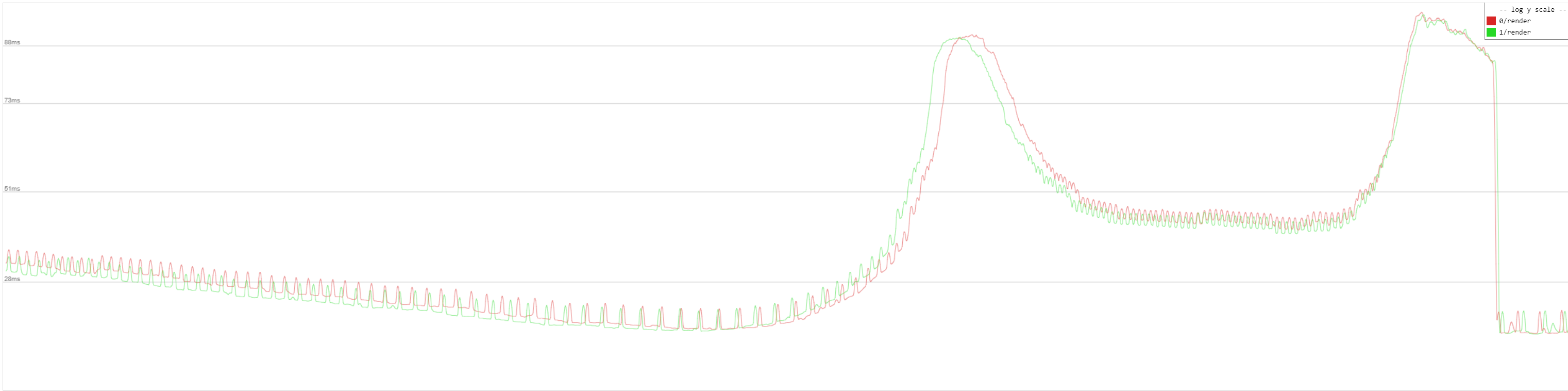
I can't notice a performance improvement. But I only checked the profiler2.

red vanilla, green patched
Feb 3 2021
I made some profiling with my new benchmark map.
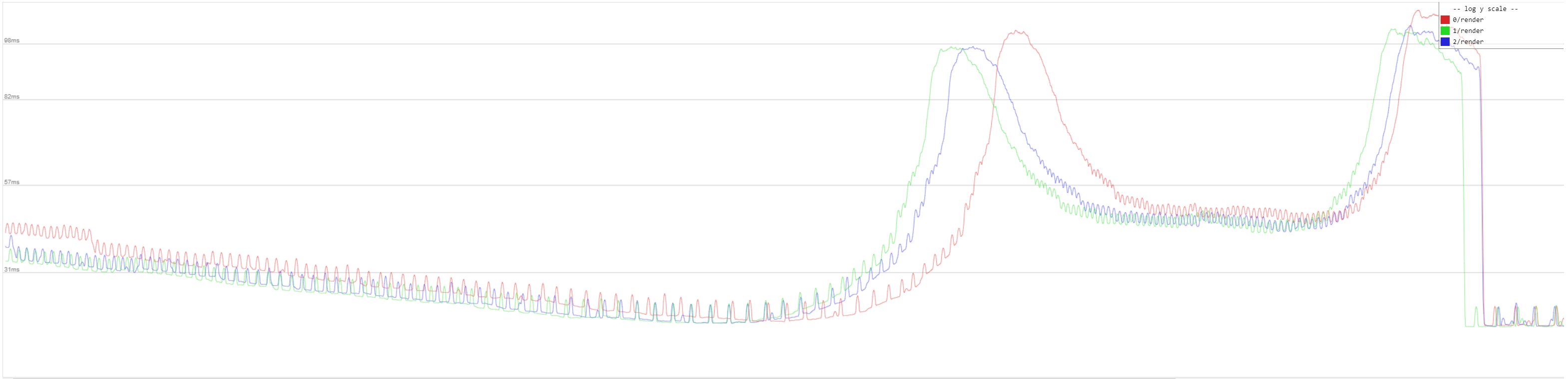
red vanilla, green deque, blue vector
Feb 2 2021
Jan 31 2021
Jan 28 2021
I profiled this patch here.
Thanks again. When my present work is finished I will submit a new patch, from the sources
folder, and submit it here.
Thank you. I'm exited to test your new patch :)
Jan 27 2021
Can you please remove the "0ad" at the beginning of your file paths and start at "source" please?
I made some performance profiling, one time with heavy graphics load and one time with heavy movement load. I didn't see any performance improvements. Are there any other scenarios I should test?
Jan 25 2021
Would have been nice, if you explained, that this is the old Persian form of "Xerxes". Xšayaṛša isn't really known ;)
Jan 24 2021
Seems like a more useful place. But maybe you should rename the files to simd.cpp/h for more general use and preparation for future usage of AVX/AVX2?
Jan 21 2021
Jan 18 2021
Update float values 0 -> 0.f (See comment)
Removes the pointer switch and replaces it with a macro condition.
First, Linux loses performance by using the SSE implementation. Therefore, this implementation is now only for Windows.
Second, we lose too much performance by using pointers. We already use SSE2 flags for Windows. For this reason, the pointers have been removed and replaced by Windows + SSE macro condition.
Jan 17 2021
Jan 16 2021
Causes #5922
Jan 13 2021
@vladislavbelov any plans to commit this improvement?
Jan 11 2021
Solved in rP24550.
No longer needed as rP24550 has been committed.
Dec 20 2020
So here ist the generated assembly for matrix multiplication, SSE2 flag enabled, MSVC2017.
Dec 19 2020
Made some performance profiling on MSVC2017, SSE2 flag enabled, Ryzen 3700X.
Dec 18 2020
GCC 10.2.0
I despise the OS solution however because it leads to unecessary macro complexity.
Maybe it's less complexity, if we only care on the architecture? So always use the SSE functions and flag on x86. As you already said, Windows doesn't support non SSE2 CPUs. If someone is using such an 20 years old, non SSE Linux PC, the computer is already to slow to run the game. So ignore them.
Dec 13 2020
Yep, the patch slowdown the performance for me.
By default the flag is already set to SSE2. (visual studio says so)
I don't know why, but it's a difference, if I set the flag in Premake instead of Visual Studio. Setting flags in VS the performance doesn't change in any way. Setting SSE2, AVX, or AVX2 flags in Premake improves the performance.
Also your profile data always have that weird offset which makes it hard to see anything
This is because you can only save the profile data at the end, not at the beginning of a session. Different framerates leads than to an offset.
Here the performance comparison of your patch.
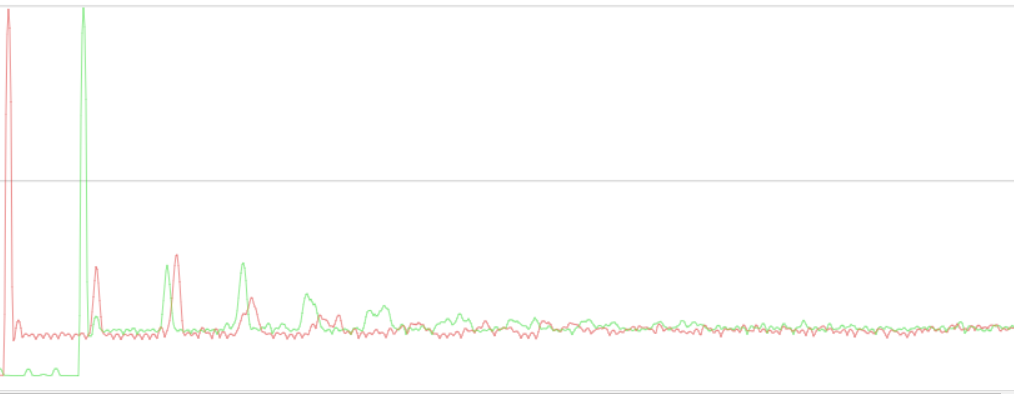
frame: red unpatched, green your patch.
Dec 12 2020
Maybe I'm a bit off topic, but do we really need those SSE functions? Can't that be done via compiler flags by the compiler itself? I think we should always compile with SSE on x86. SSE was introduced on Pentium III 1999, I guess nobody does use 21 year old hardware?
Would be also nice if wildfiregames could offer a AVX or a AVX2 release version besides the SSE version. I guess, replacing the SSE compiler flags by AVX/AVX2 flags shouldn't be that effort?
Dec 6 2020
Dec 5 2020
I made some new profiling.

Green patched - 16 threads, red without patch.
Replay and profiling data see below.
Nov 24 2020
Everything works correct again, thx.
The sharpening and anti-aliasing options fail every time the game starts. To get them work, I have always to turn them off and on.
Nov 13 2020
I tested it on my notebook Windows 10 Intel 8250U, Intel UHD 620 and on my desktop Windows AMD 3700X, AMD RX 5700. Everything works fine.
I also didn't notice any performance impact on my desktop. Is the whole calculation done by the GPU?
Nov 11 2020
I made a new profiling with deactivating instead of the patch, absolutely the same.
I suspect <prop actor="props/units/quiver_greek_back.xml" attachpoint="back"/> to be particularly slow.
You're right, this is the main point.
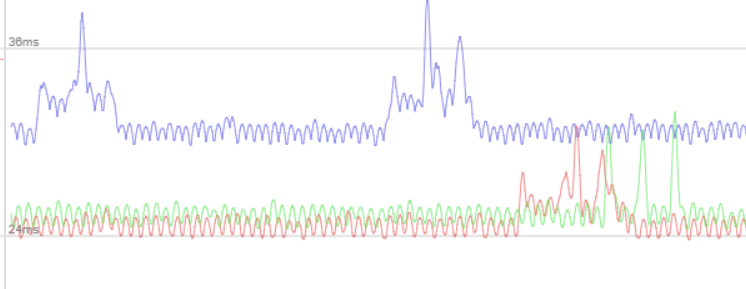
profiler2 frame: red patched, green only quiver greek back deactivated, blue old
I guess, trees could be interesting too.
Nov 10 2020
I made some profiling on the new map oceanside using athenians archers. I noticed realy big performance improvements when zooming out.
Test conditions: oceanside map, athenians archer, no moving of the units, saved at 4:30min, completely zoomed out, no moving of the camera from it's start position (only zooming out)

profiler2 frame: red old, green patched.
Nov 7 2020
Game works for me. (Ryzen 3700X, Windows)
Seems to, that the patch is needed for some AMD Threaripper CPUs.
Nov 5 2020
The Game still runs on Windows AMD Ryzen 3700X.
Nov 4 2020
I have neither noticed any issues or performance improvements. Windows, AMD Radeon
Oct 11 2020
Reupload of the newest version.
Vendor check bevor skipping the validation.
The workaround is to specific, as it seems to work only for the Ryzens. The Threadrippers still fail. A correct implementation, or a more general solution/workaround is needed.
Aug 22 2020
Patch works for me (Windows 10, RX 5700).
@vladislavbelov your former patch had AA for trees too, without a big performance hit. Does the new performance impact came from the water bugfix?
Also I don't think, we should care about performance hits by trees, as we have FXAA for lower hardware. I see no need for the implementation in the current state, as FXAA + sharpening looks better than MSAA, as long as trees have aliasing. Especially as FXAA and sharpening has no measurable performance impact compared to MSAA.
Aug 8 2020
A dying animation is not possible here? Or at least a simple visual plop effect?
Aug 7 2020
Setting it disabled doesn't change anything.
What are you reporting as being 10/20% slower exactly?
The whole frame.
Edit: I feel like your GC might be too good. Can you try capping max_matrix_uniform to maybe 64 in hwdetect.js ?
That's it. Thx
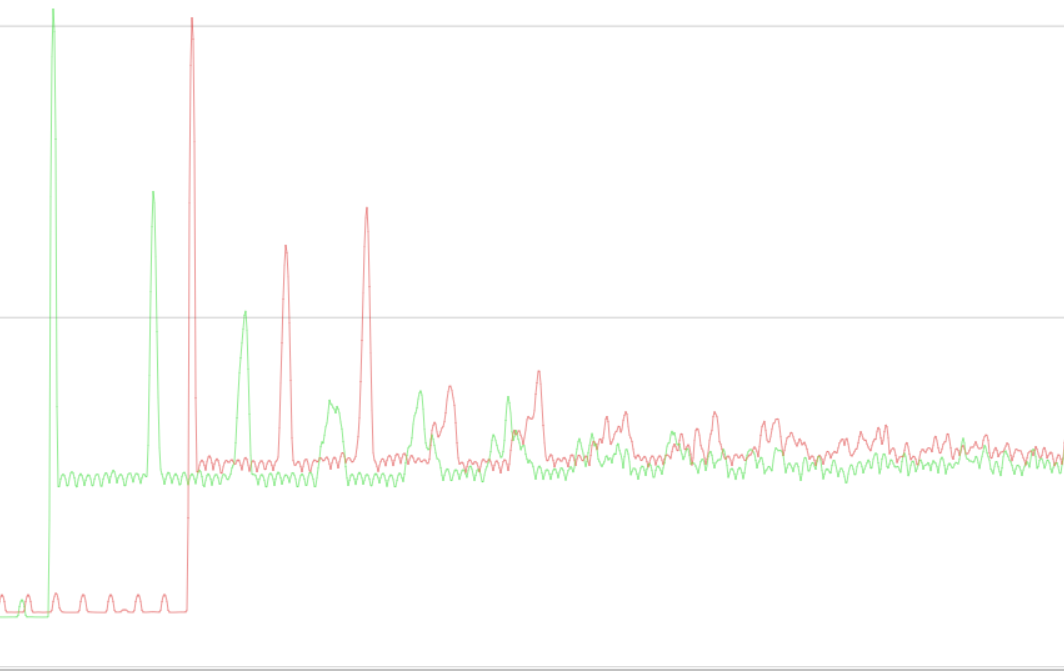
Render: red non patch, green patched.
I always use a 200 units replay on sahydian buttes, camera will not moved or zoomed. What is GPU skinning? GSLS enabled.
Edit -> Also what is your graphics card?
Radeon RX 5700
I also got this compiler warnings
\source\renderer/ModelVertexRenderer.h(158): warning C4100: "model": Unreferenzierter formaler Parameter (Quelldatei wird kompiliert ..\..\..\source\renderer\InstancingModelRenderer.cpp)
\source\renderer/ModelVertexRenderer.h(158): warning C4100: "shader": Unreferenzierter formaler Parameter (Quelldatei wird kompiliert ..\..\..\source\renderer\InstancingModelRenderer.cpp)
\source\renderer/ModelVertexRenderer.h(158): warning C4100: "model": Unreferenzierter formaler Parameter (Quelldatei wird kompiliert ..\..\..\source\renderer\HWLightingModelRenderer.cpp)
\source\renderer/ModelVertexRenderer.h(158): warning C4100: "shader": Unreferenzierter formaler Parameter (Quelldatei wird kompiliert ..\..\..\source\renderer\HWLightingModelRenderer.cpp)
\source\renderer/ModelVertexRenderer.h(158): warning C4100: "model": Unreferenzierter formaler Parameter (Quelldatei wird kompiliert ..\..\..\source\renderer\ModelRenderer.cpp)
\source\renderer/ModelVertexRenderer.h(158): warning C4100: "shader": Unreferenzierter formaler Parameter (Quelldatei wird kompiliert ..\..\..\source\renderer\ModelRenderer.cpp)
I made some quick profiling. I noticed that the amount of draw calls is halfed. I also tested value 1 against 64. 64 is much faster. But compared to the non patched replay, there was a performance hit by ~10-20%.
Does this hit come from your new profiler option "saved draw calls"? I think some calculations of profiler are active, even if you don't have open the profiler panel. Do you have a non profiler version to test?
Aug 6 2020
Jul 25 2020
Jul 24 2020
Edited the sharpness initialization. Disables sharpening, if post progressing, or GLSL, is disabled.
Jul 23 2020
Jul 22 2020
Updated the versioning of the used GLSL version.
I made some profiling with different numbers (1, 2, 3, 4, 5, 6, 8, 12, 16) of threads. If I compare the results, I guess, more than 16 threads wont improve the performance further.
Jul 18 2020
Didn't find the cause yet. But I recognized, that the profiler gains these pikes very much. Without the framedrops were much lower.
Jul 10 2020
Oh, I think they changing the instructions by runtime, doesn't they? A bit ugly, I think, but we could use FMA :)
Can you figure out what's causing the spikes?
I will try, but on an first look, the profiler doesn't show me something useful.
Updated the year of the license header.
Jul 9 2020
Including the SSE header, because Vulcan fails for the none Windows tests.
Removed the AVX and FMA version, as we don't be able, to change instructions by runtime. Furthermore the AVX instructions aren't faster than SSE here.
I have rewrite the patch, so it uses only SSE. That I have used for the profiling. I will upload it later this day.
I tested the build flags, SSE seems to be the only flag with an positiv impact. AVX2 makes everything worse. I also made some profiling.
Current version:
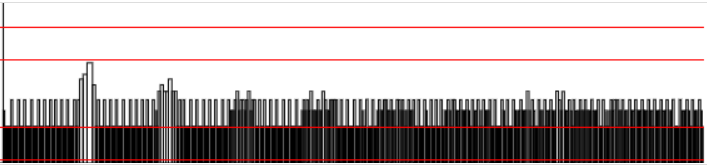
Jul 3 2020
The hardware request doesn't work, like it should.
Jun 18 2020
No it isn't. It's currently independent. I have also tried to lock postproc, to lock antialiasing, but that doesn't work. It would only lock postproc. A bit strange I think.
Edit some comments.